
1. Introduction
모든 실험은 python 3.6, Pytorch 1.7.0 에서 진행되었음을 알려드립니다.
해당 글은 Pytorch에서 Single-GPU와 Multi-GPU의 차이를 이해하고 직접 실험해 볼 수 있는 환경을 제공하기 위함을 알려드립니다.
오늘 설명드릴 목차는 다음과 같습니다.
- Experiment setting
- Single-GPU vs Multi-GPU (DataParallel) 기본 이해
- Single-GPU vs Multi-GPU (DataParallel) 결과 비교
- Multi-GPU (DataParallel) 의 문제점
2. Experiment Setting
Single-GPU와 Multi-GPU의 차이에 대해 글로 설명을 드릴거지만 직접 코드를 돌려보면서 이해하시는 게 도움이 더 잘 될것이라 생각됩니다.
그래서 비교를 위한 Experiment setting에 대해 간략하게 설명드리겠습니다.
- Dataset : CIFAR-10
- Image shape : 112(H) x 112(W) x 3(C)
- Class number : 10
- Model : MobileNetv2
- Optimizer : SGD
- Scheduler : Cosineannealing
- Loss : CrossEntropy
- Batch size : 256
fair한 비교를 위해 dataset, model, train configuration을 동일하게 설정하였습니다. 특이점은 실제 CIFAR-10의 image size가 32 -> 112로 변경되었습니다. 변경 이유는 Multi-GPU를 사용하였을 때 극명한 차이를 보여드리기 위함이에여!
3. Single-GPU vs Multi-GPU (DataParallel) 기본 이해
이번 글에서는 Pytorch에서 Single Machine에서 Multi-GPU를 쓸 수 있는 가장 간단한 방법인 torch.nn.DataParallel를 소개할게요.
os.environ['CUDA_VISIBLE_DEVICES'] = '1, 2, 3, 4' # what GPUs you will use
device = torch.device('cuda:0' if cuda else 'cpu')
model = torch.nn.DataParallel(model) # convert model to DataParallel (DP) model
model.to(device)
...
outputs = model(images)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()Multi-GPU를 사용하기 위해 torch.nn.DataParallel function인자에 Multi-GPU로 training하고 싶은 model만 넣어주면 됩니다.
torch.nn.DataParallel를 사용하였을 때 model의 forward와 backward는 다음과 같이 작동합니다.
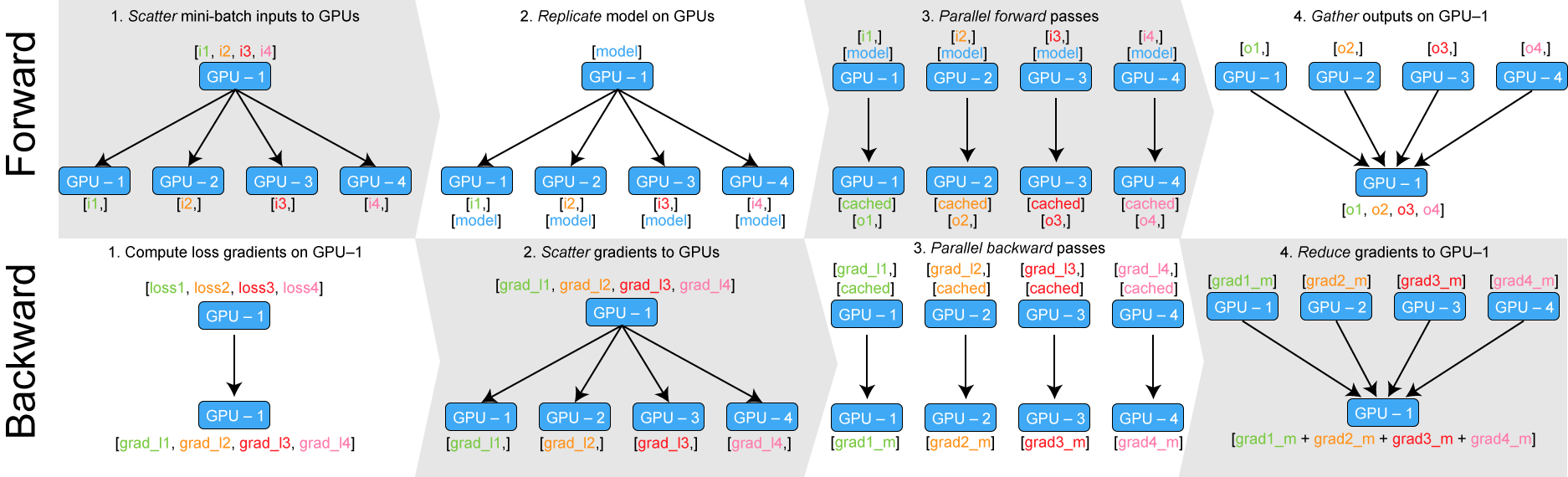
- Forward process
- GPU 1가 master GPU로써 batch를 사용하는 GPU 개수(4개)로 나누어 줍니다(scatter).
- Model를 GPU 수만큼 복제(replicate)합니다.
- 나누어진 batch를 각각 복제된 model에 forwarding해줍니다.
- forward된 outputs을 master GPU에 다시 모아줍니다(gather).
- Backward process
- Master GPU에서 loss를 compute합니다.
- 계산된 loss를 GPU 개수(4개)로 나누어 보내줍니다(scatter).
- loss로부터 각 GPU에서 backwarding를 통해 gradient를 구해줍니다.
- 각 GPU에서 계산된 gradient를 master GPU에 모아줍니다(reduce).
- Master GPU에서 weight를 update해줍니다.
실제로 위의 과정이 일어나는 지 확인하기 위해 다음과 같은 변수 value 및 size를 print 해보겠습니다.
먼저 mobilenetv2의 forward 함수에서 input과 output의 size를 출력해보겠습니다.
def forward(self, x): # in mobilenetv2.py
input = x
print(f'Input size: {input.size()}')
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
output = x
print(f'Output size: {output.size()}')
return outputOut:

총 4개의 GPU를 사용하였고 Batch size가 256개 이므로 각 GPU에서 64개 batch단위로 forward하게 되는것을 확인가능합니다.
그리고 다음과 같이 위 코드에서 output자체를 출력해볼경우에도 각 device에서 서로 다른 batch image를 처리하는 것을 알 수 있습니다.
Out:
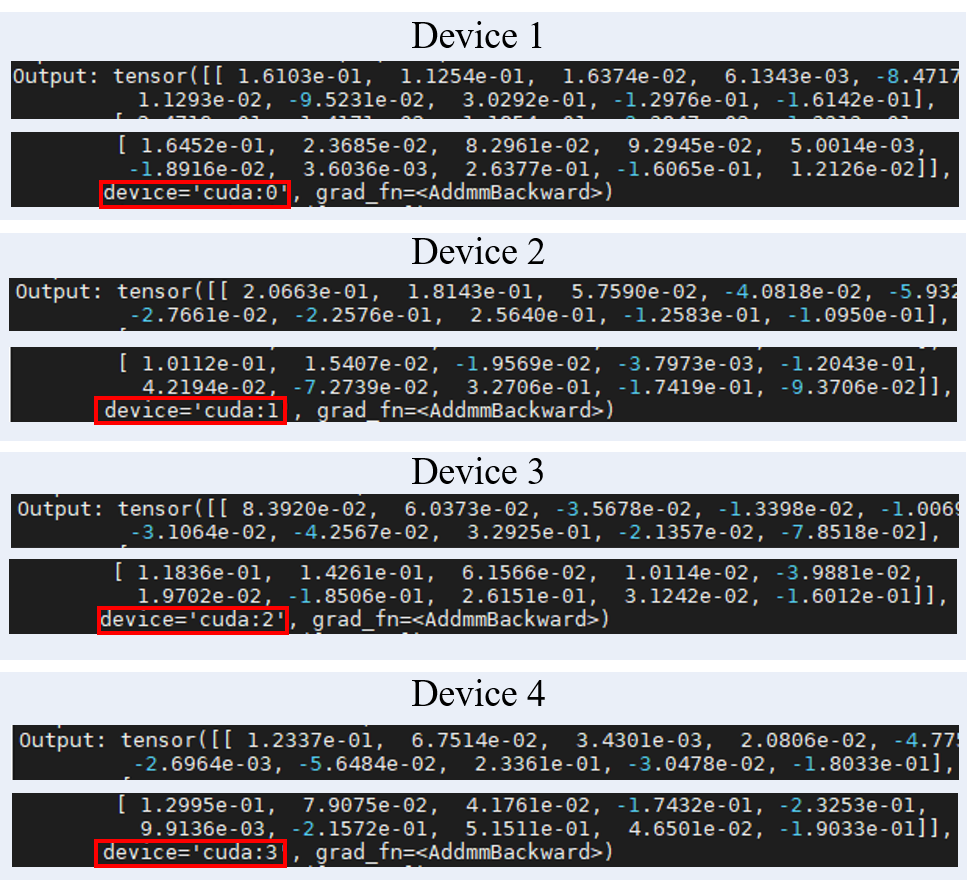
다음으로는 나누어진 outputs들이 합쳐지는 지 다음과 같은 코드로 확인해보면
outputs = model(images)
print(f'Output: {outputs}')
print(f'Output size: {outputs.size()}')Out:
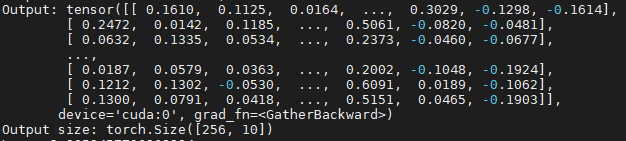
각 GPU에서 forwards된 outputs이 master GPU(cuda:0)에 합쳐지는 것을 볼 수 있습니다.
4. Single-GPU vs Multi-GPU (DataParallel) 결과 비교
Mobilenetv2 model에서 총 10epoch을 돌려 Single-GPU와 Multi-GPU의 elapse time를 비교하겠습니다.
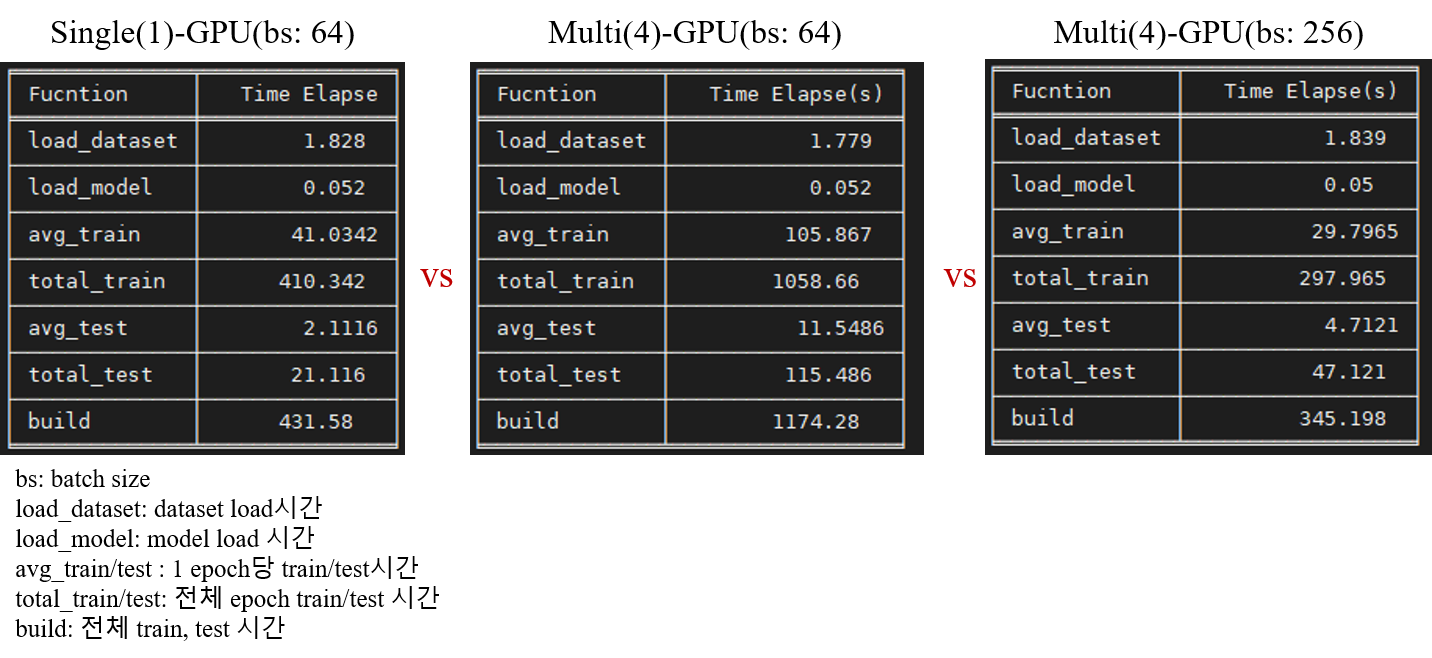
위의 그림에서 볼 수 있듯이 같은 batch일 경우는 Multi-GPU의 효과를 보기 힘드네요. 추측해본건데 같은 batch일경우
Dataparallel사용에 따른 scatter, replicate, gather 과정이 추가되므로 속도가 저하되는 것 같습니다.
MobileNetv2 모델하나로 판단하는 게 generality가 떨어진다고 생각되어 ResNet50으로도 돌려보았습니다.
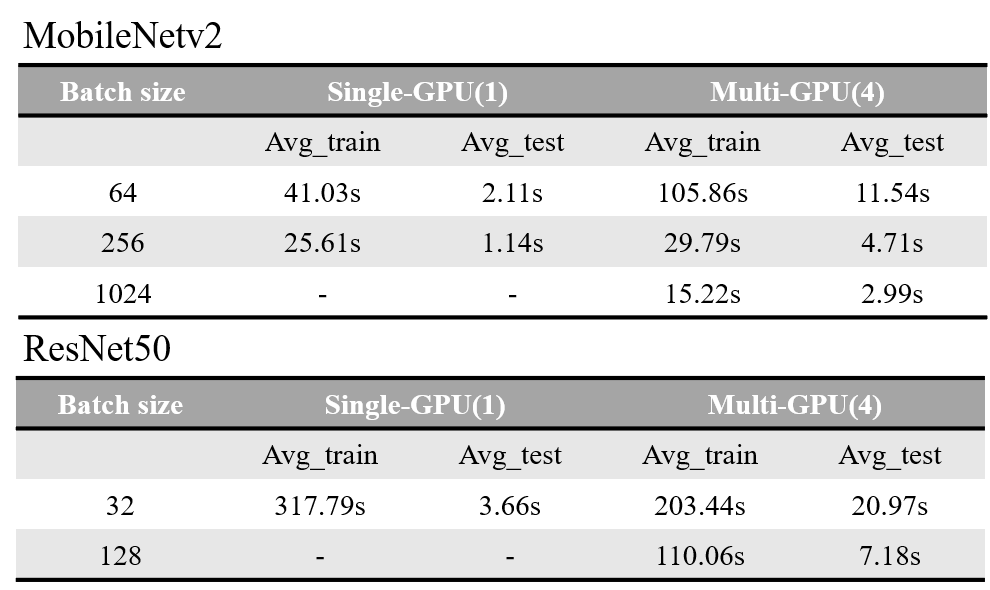
분석하자면 다음과 같습니다.
- 상대적으로 모델이 작은 MobileNetv2에서 Multi-GPU의 time computation효과를 보기 위해서는 batch size를 늘려야한다.
- 반대로, 모델이 큰 ResNet50에서는 Single-GPU와 비교했을 때 같은 batch size이더라도 Multi-GPU로 나누어 training하는 게 더 빠르다.
- Multi-GPU를 사용한 모델의 test inference time이 Single-GPU보다 높다.
5. Multi-GPU (DataParallel) 의 문제점
이 Section에서는 Dataparallel을 썼을 때의 문제점을 정리해보고 그에 대한 해결방안이 무엇이 있는지 알아보겠습니다.
먼저 Dataparallel의 문제점은 크게 2가지입니다.
- 추가적인 resource사용이 요구된다.
위에서 언급드린 (a) 매 iteration마다 model를 replicate하고 forward시켜야 한다. (b) gather, reduce 작업이 추가로 요구된다.
라는 process때문에 training time을 더 효율적으로 줄일 수 없다고 합니다.
- single-process multi-thread parallelism이 GIL에 의한 방해를 받는다
먼저 GIL이란 Global Interpreter Lock 의 약자인데 여러개의 쓰레드간의 동기화를 위해 사용되는 기술인데 동시에 하나 이상의 쓰레드가 실행되지 않게 합니다.
예를 들어 3개의 thread가 동시에 cpu를 점유할 수 없습니다. 즉, 멀티 쓰레드 프로그래밍해도 성능이 향상되지 않는다는 말이다.
이 기술을 쓰는 이유는 만약 parallel 한 multi-threads 구현체들을 사용할수 있도록 할 경우(GIL을 쓰지 않을 경우) single thread만 사용하는 경우의 성능 저하를 만들어낸다.
그래서 정리하자면 GIL때문에 DataParallel사용 시 multi-thread paralleslism이 잘 작동하지 않는 것이다. 그렇다면 이를 해결하기 위해 Pytorch에서는 DistributedDataParallel을 사용하기를 권장하는데 이는 다음 글에서 만나보자.
해당 실험에 대한 코드는 Pytorch_MultiGPU에서 사용가능합니다~~
'AI Engineering > PyTorch' 카테고리의 다른 글
| PyTorch training/inference 성능 최적화 (2/2) (2) | 2022.11.22 |
|---|---|
| PyTorch training/inference 성능 최적화 (1/2) (0) | 2022.11.13 |
| Mixed Precision Training 이해 및 설명 (0) | 2022.11.02 |
| [Torch2TFLite] Torch 모델 TFLite 변환 (feat. yolov5) (1) | 2022.06.26 |
| PyTorch MultiGPU (2) - Single-GPU vs Multi-GPU (DistributedDataParallel) (0) | 2022.03.12 |