
0. Machine Learning pipelining
(ML pipelining 필요성 및 동기에 대한 밑의 단락입니다 읽어보세용!)
기업에서 ML model을 서비스할 경우 정제되어 있는 데이터셋은 없으며, 주기적으로 라벨이 수정되거나 새로운 데이터가 끊임 없이 계속 쌓이거나 바뀌게 됩니다. 그때마다 새로 training dataeset을 구성해야 하며, validation set 또한 주기적으로 업데이트해야 할 것입니다. 또한, 좀 더 유저 경험을 고려한 새로운 evaluation metrics를 개발해야 하며 model serving이나 monitoring, data와 model의 버전 컨트롤까지 고려해야합니다. 그래서 data가 업데이트될 때마다, model이 변경될 때마다, error가 발생하거나 원하는 수준의 성능이 나오지 않을 때마다, 매번 일일이 dataset을 다시 구성하고 학습 스크립트를 실행하고, 평가를 진행하는 등 모든 과정에서 많은 노력과 시간을 필요로 하게 됩니다.
이를 해결하기 위해 각 과정들의 in/out만 표준화 하고 각 task의 결과에 따른 조건부 처리 및 trigger설정하여 pipeline에 맞춰 실행하는 workflow를 만든다면 반복적인 과정을 줄일수 있으며 이는 engineer/scientist가 model 개선과 연구에만 집중가능하게 합니다.
1. Airflow란?

Apache airflow는 python기반의 workflow mangement platform으로 여러가지 tasks을 일련의 그래프로 연결하고 스케줄링, 모니터링 등 piepline 관리를 위한 다양한 기능을 제공합니다. 즉, airflow는 data processing tool이 아니며 data processing하는 데 있어서 필요한 서로 다른 task를 orchestrating하는 것입니다.
Airflow는 다음 그림과 같이 task(compoenent)들이 directed acyclic graph(DAG)형태로 구성되어있습니다. 그래서 전체 task들은 순환(cyclic) 구조를 가지지않으며 각 task는 하나의 node를 뜻하며 edge를 통해 task간의 의존성을 나타냅니다.
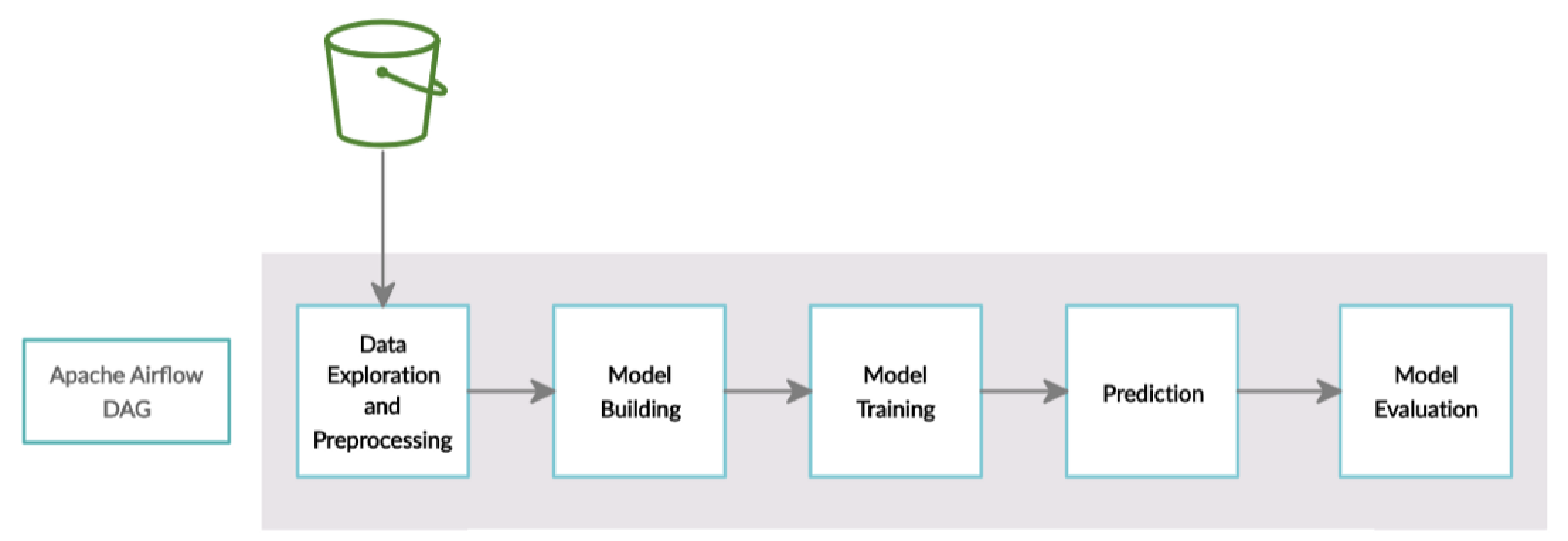
1.1 Airflow를 써야하는 이유
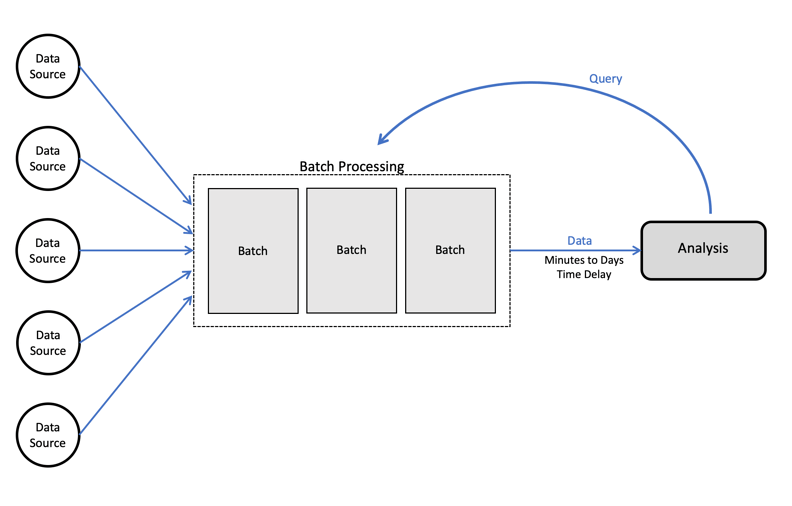
- batch-oriented task를 서비스할 경우 사용합니다. (아래 그림 참조)
- batch-oriented란 특정 size만큼(batch)의 데이터를 처리하는 것을 반복
- 실시간 데이터를 처리하는 streaming pipeline서비스를 처리할경우 airflow는 적합하지 않을 수 있음
- python code로 복잡한 pipeline을 implement가능합니다.
- Airflow이 python 기반이므로 많고 다양한 system(DB, cloud services, ...)과의 integration 및 extension이 가능합니다.
- 일정 interval마다 pipeline을 스케줄링가능하며 backfilling을 통하여 historical data를 쉽게 re(process)가능합니다.
- backfill에 대해서는 추후에 더 자세하게!!
- web interface를 제공하며 이는 pipeline의 결과를 모니터링하고 디버깅하기 좋습니다.
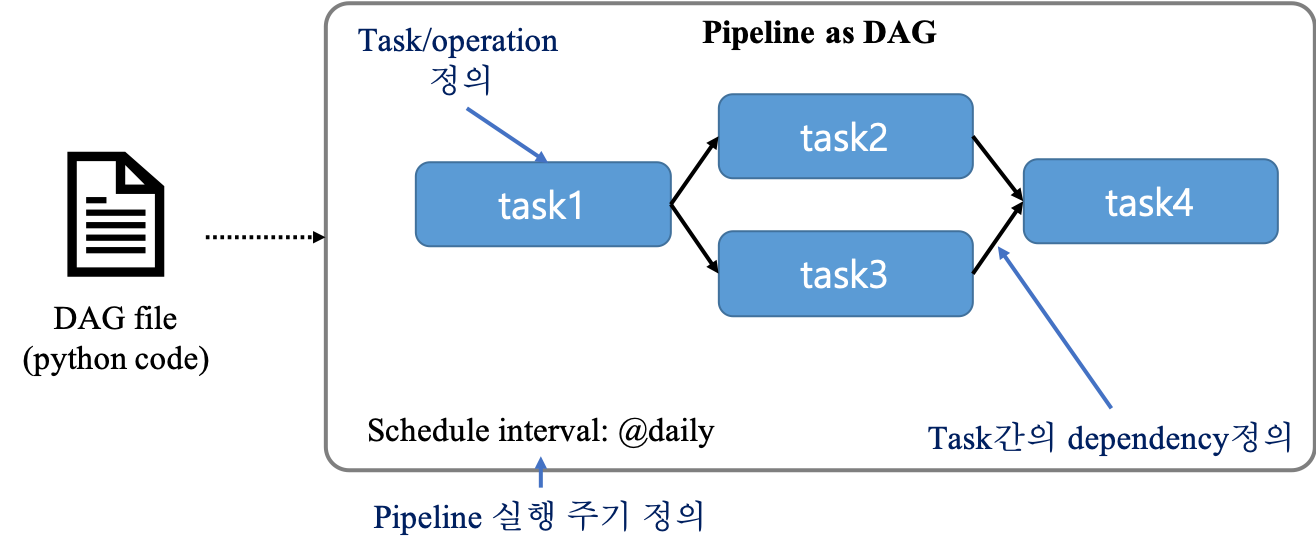
1.2 Airflow pipelinling 정의 방법
Airflow는 pipeline을 DAG형태로 구성합니다. DAG는 DAG files안의 python code를 사용해서 정의가능합니다. python code로 각 task(node)를 정의할수 있으며 task간의 dependency와 해당 pipeline의 실행 시간,주기까지 설정가능합니다. python code를 통해 DAG를 만들어 보는 것은 다음 글에서 진행해보도록 하겠습니다.
1.3 Airflow 구조
위에서 정의된 pipeline은 airflow가 어떻게 실행시키는 지 알려면 airflow의 구조를 이해하셔야합니다. Airflow는 크게 다음과 같이 3가지의 main components로 구성되어있습니다.
- Airflow scheduler
- DAG를 parsing하며 해당 pipeline의 실행 start와 interval을 scheduling을 하여 Airflow worker(s)에게 task를 전달
- Airflow worker
- 각 task를 실제로 실행시키는 주체
- Airflow webserver
- parsing된 DAG를 시각화하며 DAG의 실행과 결과에 대해 모니터링가능하게 해줌
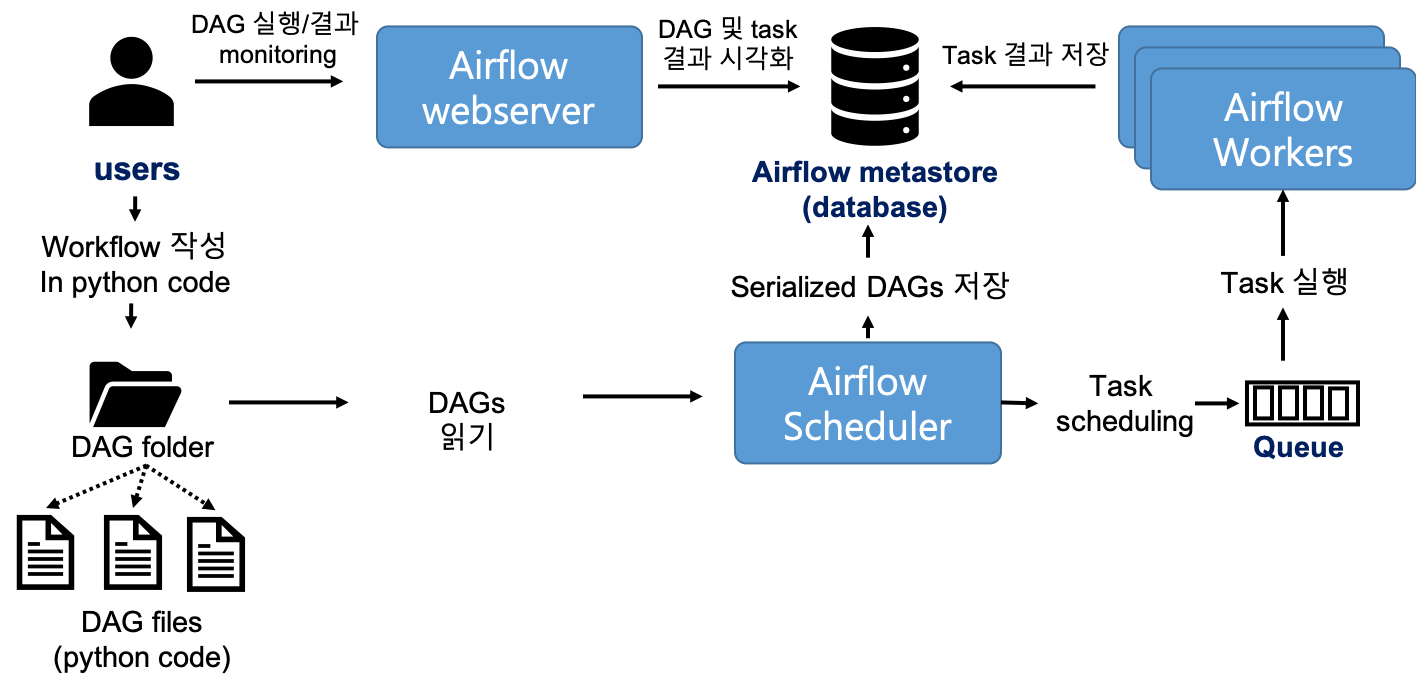
Airflow scheduler는 Airflow의 핵심이며 우리가 설계해놓은 pipeline을 처리하는 시간 및 방법을 모두 결정하게 됩니다. 조금 더 디테일하게 scheduler내부 동작 방식을 보면 다음과 같습니다.
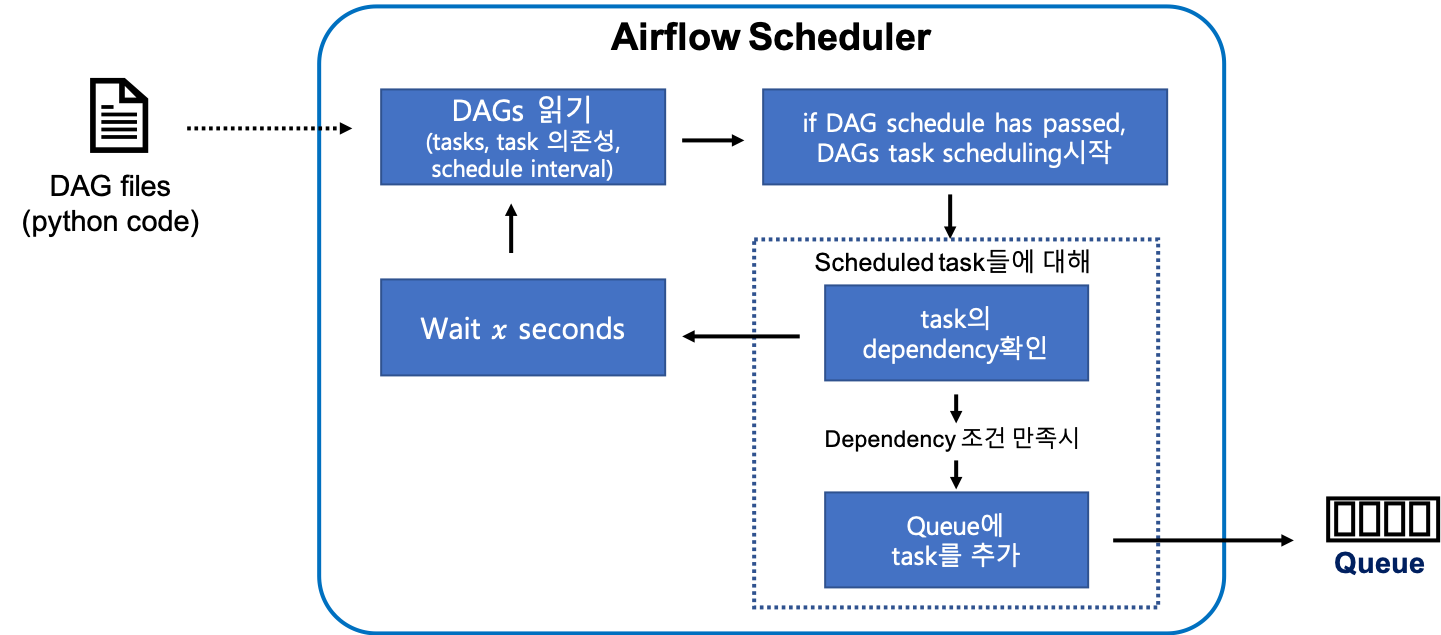
- scheduler는 유저가 만든 DAG file을 읽음
- DAG file에 정의된 execution start time과 interval에 맞춰 DAG task들을 스케줄링
- 스케줄링된 task(A)가 다른 task(B)에 의존성 판단
- task A가 task B에 의존되어있고 task B가 완료된 경우 queue에 task A 추가
- 의존하고 있는 task B가 끝나지 않은 경우 일정 시간 기다림
위의 모든 과정 및 결과들은 airflow의 metastore에 저장되므로 유저는 task의 진행상황이나 로그들을 metastore와 연동되어있는 airflow webserver interface를 통해 확인가능하다.
2. Airflow 설치
MacOS 12.1, anaconda, python 3.9, airflow 2.2.3 환경에서 실습을 진행함을 알려드립니다.
먼저 anaconda에서 실습을 진행하기 때문에 다음과 같이 pip가 anaconda에서 사용됨을 확인하고 airflow을 설치합시다.
pip --version
pip install apache-airflow
설치가 다 되었다면 airflow version 명령어를 통해 설치가 잘 되었는 지 확인합니다. 그리고 default로 airflow 디렉토리는 home디렉토리에 저장되기때문에 다음과 같이 확인가능합니다.

2.1 Airflow DB initialize
DB를 초기화 합니다. 이를 통해서 예제 pipeline들이 생겨나기도 합니다.
airflow db init2.2 Airflow scheduler 실행
위에서 설명드린 airflow scheduler를 실행하는 명령어 입니다.
airflow scheduler
2.3 Airflow webserver 실행
airflow webserver를 실행시킵니다. -p옵션은 port를 의미합니다.
airflow webserver -p 8080위의 명령어가 정상적으로 작동되었다면 이제 웹에서 localhost:8080에 들어가보면 다음과 같은 화면이 나오는지 확인합니다.
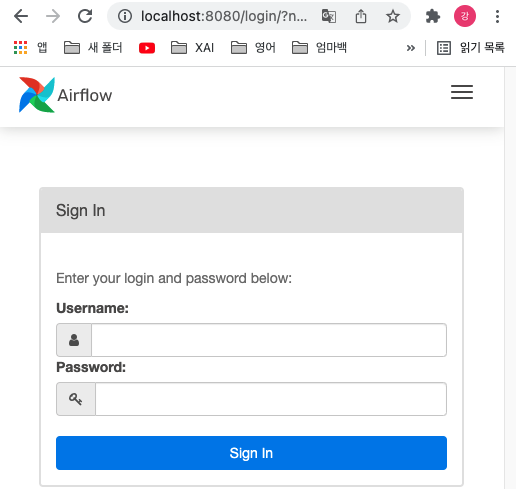
webserver에 접속하니 airflow의 username과 password가 필요합니다. 그렇다면 airflow cli를 통해 유저를 생성해봅시다.
airflow users create --role Admin --username admin --email admin.com --firstname sinhan --lastname kang --password admin
Admin계정으로 user를 생성하였고 username과 password는 동일하게 admin으로 지정하였습니다. 생성된 유저 정보는 airflow users list명령어로 확인가능합니다. 확인하였다면 webserver에 만든 유저 정보로 다음과 같이 로그인가능하게 됩니다.

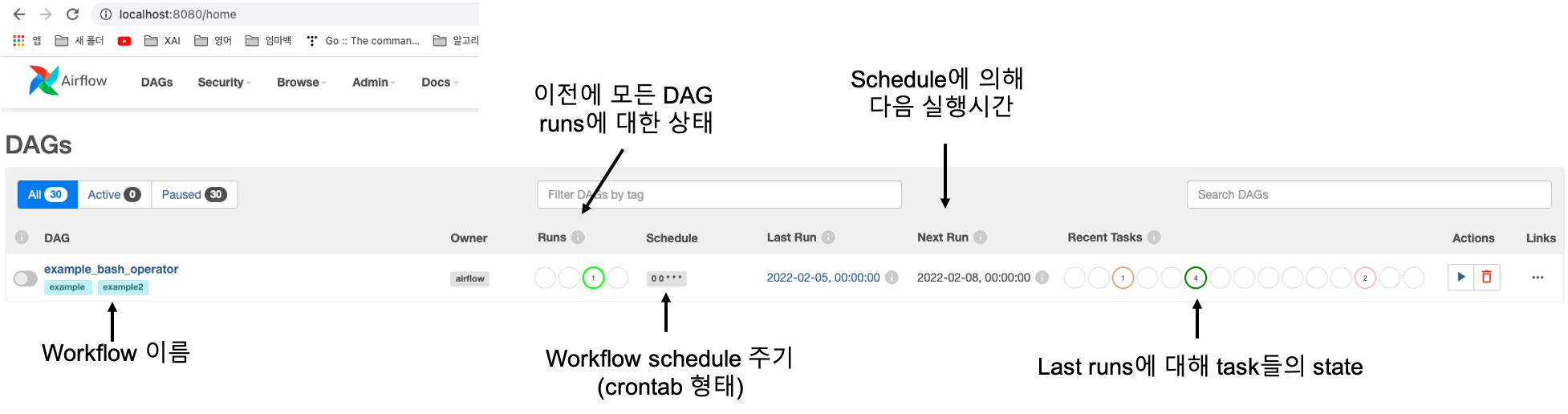
위 그림에서 DAG의 example과 각 column이 의미하는 내용을 적어놓았습니다. schedule부분에서 crontab형태로 나타냅니다. (모르시면 구글링!) 다음과 같은 그리고 example_bash_operator를 클릭하고 'Graph'라는 menu선택을 하면 다음과 같이 해당 workflow의 DAG를 확인가능합니다.
해당 example들은 db initialize를 통해 생성된 것이며 airflow dags list명령어를 통하여 webserver에서 보이는 example들을 terminal에서 볼 수 있습니다.
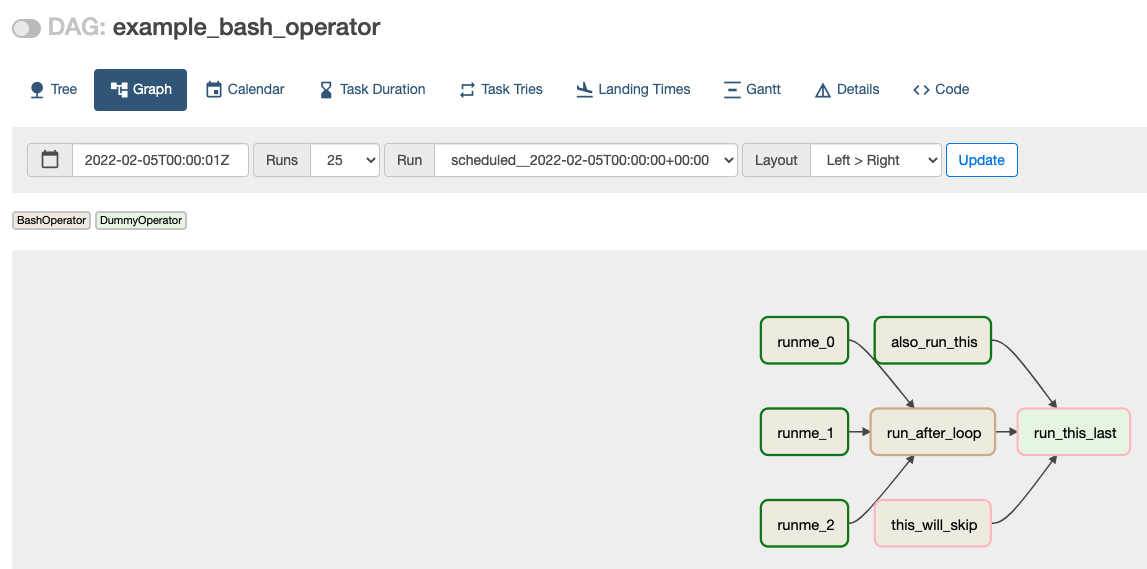
다음 글에서는 위의 예제와 같이 DAG를 python code로 만드는 법과 실제로 workflow를 실행시켜보면서 결과를 얻어보도록 하겠습니다.
Appendix
혹시 다음과 같은 warning이 뜬다면 sqlalchemy버전이 너무 높아 생기는 것이므로 다음과 같은 명령어로 warning을 해결가능합니다.
# warning: add the parameter 'overlaps="dag_run"' to the 'SerializedDagModel.dag_runs' relationship
pip uninstall sqlalchemy
pip install 'sqlalchemy < 1.4.0'
'AI Engineering > MLOps' 카테고리의 다른 글
| [BentoML] ML model serving 방법 (feat. YOLOv8) (0) | 2023.05.22 |
|---|---|
| Airflow (2) - DAG workflow 작성 및 실행 (0) | 2022.03.16 |
| Docker/Kubernetes - (12) Kubernetes Ingress (0) | 2022.03.15 |
| Docker/Kubernetes - (11) Kubernetes 리소스의 관리와 설정 (0) | 2022.03.15 |
| Docker/Kubernetes - (10) Kubernetes 이해 및 사용 (0) | 2022.03.15 |