
A. Model & Module
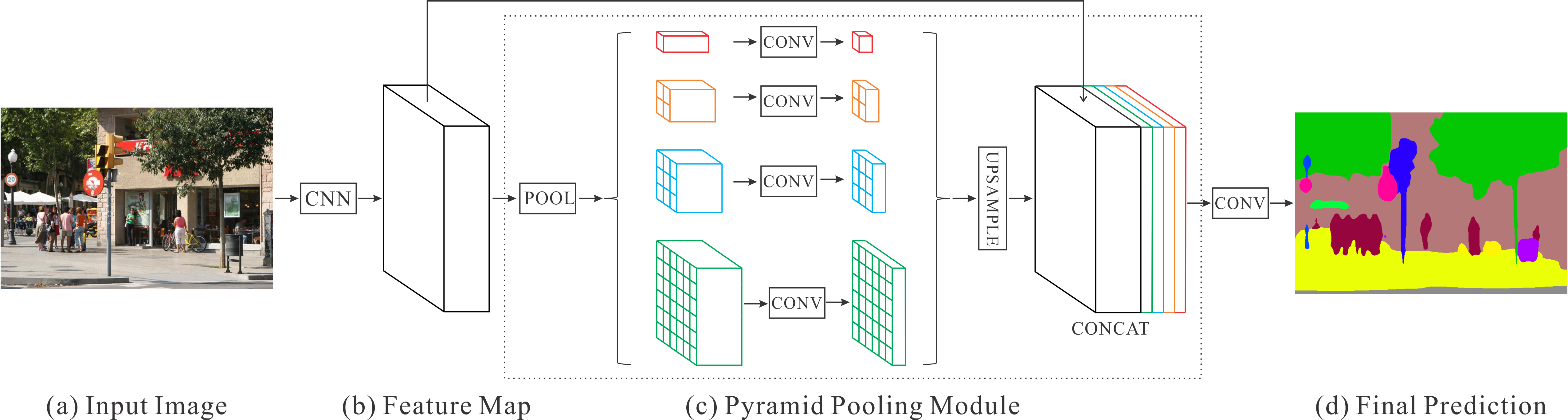
- Pyramid Pooling Module(PPM): 기존의 local feature(b)와 pooling을 통한 global feature(c의 색깔 있는 output들)을 모두 학습하기 위함
- 서로 다른 kernel size로 여러 차례 avg pooling(논문에서 1x1, 2x2, 3x3, 6x6 kernel size 사용)
- 1x1 size의 feature map은 가장 global feature이고 feature map size가 커질수록 local feature에 가까워짐
- 1x1 convolution을 통해 channel 수를 조정
- pooling layer의 개수를 N이라고 할 때, 출력 channel 수 = 입력 채널 수 / N
- input size에 맞춰 feature map을 upsample(bilinear interpolation)
-
원래의 feature map과 생성된 새로운 feature map들을 concatenate
- 서로 다른 kernel size로 여러 차례 avg pooling(논문에서 1x1, 2x2, 3x3, 6x6 kernel size 사용)
- SE(Squeeze & Excitation) Module: channel relationship에 초점을 맞추어 학습에 중요한 channel에 가중치를 주는 방법
- \(U \)의 \(C \)는 각각이 고유한 특징을 가짐, \( U \)에 대해 squeeze operation(global avg pool)을 진행하여 \( U\)를 대표하는 feature vector \( 1 \times 1 \times C \)을 뽑음
- Channel간의 relationship을 feature map \( U \)에 적용시키기위해 다음과 같이 Excitation operation 진행
- Excitation은 FC1(T) - ReLU(T) - FC2(C) - Sigmoid(C)로 구성 (각 layer옆은 output channel을 의미, \(T < C \))
- FC1 layer와 ReLU을 통해 \(C\)보다 작은 \(T\)채널로 수축시켜 channel간의 관계를 고려할수 있게 함
- FC2 layer를 통해 원래 채널수 \( C \)로 돌려놓고 sigmoid를 통해 가중치 형태인 0~1값 갖도록 하여 \( U \)에 곱해줌

B. Loss
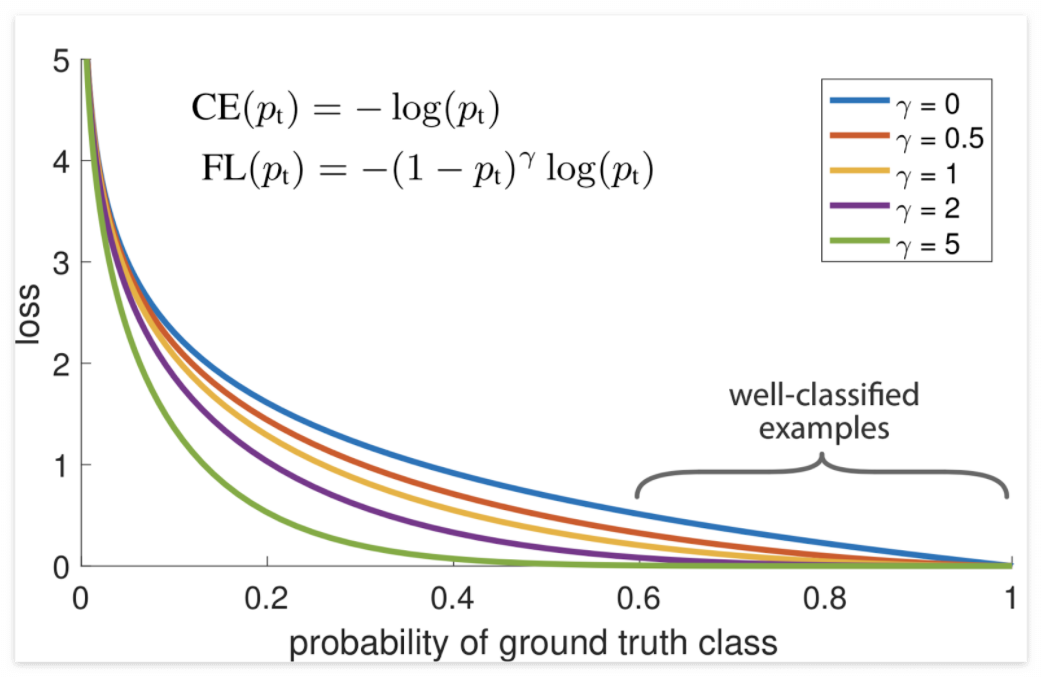
- Focal loss: CE에서 well-classified(easy sample)에 대해서는 loss를 더 작게 만들기 위해 \( (1 - p_t)^\gamma \)을 추가
- 아래는 label이 1인 경우의 loss식이며 \( p_t \)가 1에 가까울 수록 \( \gamma \)에 의해 loss가 exponential 하게 작아지게하여 상대적으로 easy sample의 loss를 CE때보다 급격히 줄임
- \( \gamma \)가 0일때 CE랑 같음
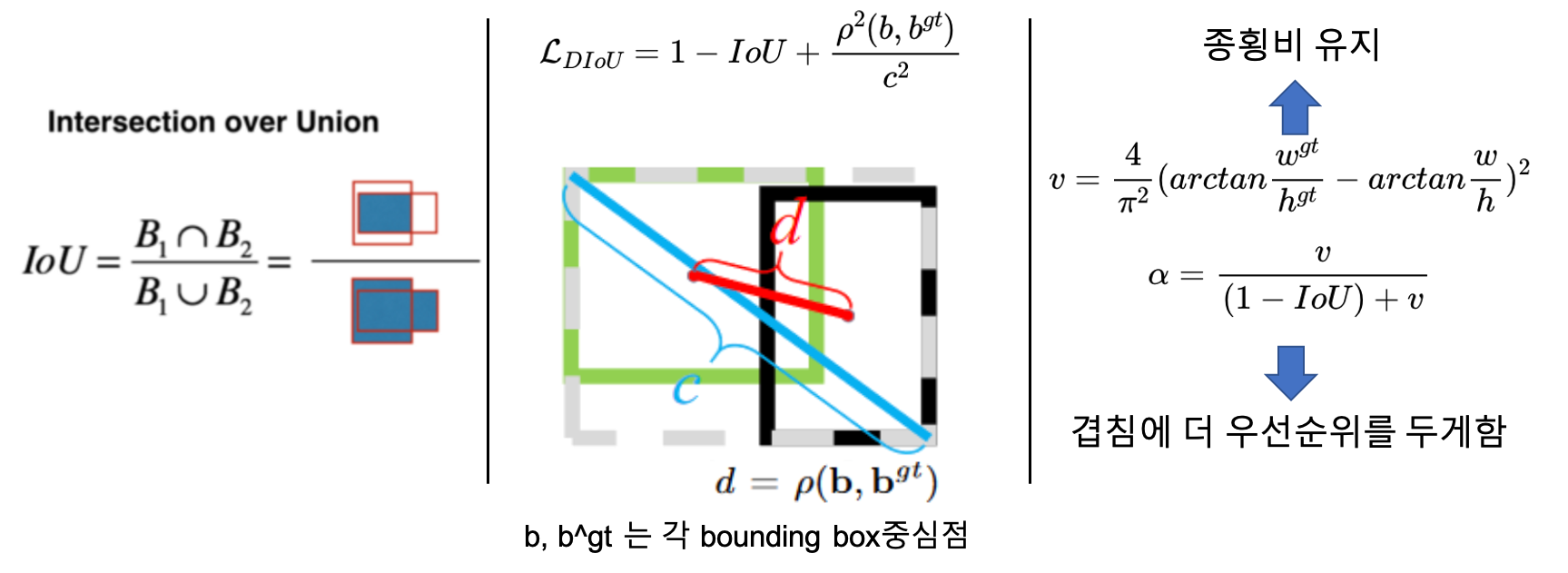
- CIoU loss: 겹치는 영역(IoU), 중심점 사이의 거리, 종횡비 세가지 메트릭을 동시에 고려한 것 (DIoU의 확장버전)
- \( CIoU = 1- IoU + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v \)
C. Optimizer
D. Data Augmentation
- CutMix (CVPR 2019): 모델이 객체의 차이를 식별할 수 있는 부분에 집중하지 않고, 덜 구별되는 부분 및 이미지의 전체적인 구역을 보고 학습도록 하여 일반화와 localization 성능을 높이는 방법.
- OOD(out-of-distribution)와 이미지가 가려진 sample, adversarial sample에서의 robustness도 좋은 성능

- Copy & Paste (CVPR 2021) : Segmentaiton에서 사용가능

E. Engineering
- Pytorch training 최적화: 요기
- Pytorch output slicing을 통한 loss 계산시(graident에 사용되는) 주의점
- If the shape of output is (4(B), 2(C), 320(W), 320(H)]
- Wrong → out1 = output[:, 0, :, :], out2 = output[:, 1, :, :]
- Correct → out1 = output[:, :1, :, :], out2 = output[:, 1:, :, :]
- SOD에서 encoder(i.e. resnet, efficientnet)의 low level feature는 너무 많은 details을 가지는 반면에 high level feature는 rough한 결과를 내뽑음 (Reference: Pyramid Feature Attention Network for Saliency detection)
- Low level feature에는 detail이 많고 sod는 boundary를 찾는 게 목적이니 spatial attention을 사용
- High level feature에는 rough한 영역이 많으니 channel attention을 통해 high response를 내는 channel에 가중치 줌 (salient object찾는데 좋음)
- Low level feature + high level feature를 aggregation하고 channel attention, spatial attention한 논문이 Tracer(AAAI 2022)

반응형