※ 해당 블로그를 reference하였습니다.
1. Per-shot Encoding 이란?
Conventional Encoding 방법은 하나의 video에 대하여 압축의 정도를 결정하는 Quantization Parameters(QPs)(e.g. CRF)값 '하나'을 인자로 encoding하는 방법을 취합니다. (CRF값이 클수록 compression을 많이 하게 되고 visual quality는 낮아집니다.)
하지만 이는 video내의 frame간의 특성을 고려하지 않은 채 단일한 QPs로 encoding하기 때문에 B(Bitrate)-D(Distortion) rate관계에서 최적의 성능을 뽑아내지 못합니다. 예를 들어, 한 video내의 초중반 frame들은 flat region이 많고 motion vector의 값이 작은 경우이고 중후반 frame들은 그 반대일 경우 하나의 CRF값으로 해당 video를 encoding하는 것은 효율적이지 않겠죠.
이를 해결하기 위해 Per-shot Encoding은 하나의 video를 여러 개의 shot으로 split한 다음에 각 shot마다 적절한 CRF, Resolution값을 encoding하고 concatenate하는 방법을 의미합니다. 각 shot마다 적절한 CRF와 Resolution을 주어 encoding가능하므로 B-D rate효율이 좋을 것입니다. Per-shot Encoding은 Dynamic Optimizer라고도 명명하며 Netflix에서 제안한 방법입니다.

또 다른 특징으로는 per-shot encoding은 shot마다 병렬적으로 encoding처리가 가능하고 하나의 shot에서 encoding error가 발생해도 오류가 발생한 shot만 다시 encoding하면 된다는 장점을 가집니다.
이후에는 좀 더 구체적으로 (i) 어떤 방법으로 video을 여러 개의 shot으로 나누는 지? (ii) 각 shot마다 적절한 CRF 값은 어떻게 찾는 지에 대한 방법은 Per-shot Encoding 알고리즘을 설명하면서 공유드리겠습니다.
2. Per-shot Encoding 알고리즘
Per-shot Encoding은 video을 입력으로 (1) Scene Detection을 통해 여러 개의 shot으로 나누고 (2) 각 shot별로 다양한 encoding configurations(e.g. CRF, Resolution, ...)을 인자로 encoding합니다. (3)
2.1 Scene(Shot) Detection
Per-shot Encoding은 video을 입력으로 받아 scene detection을 통해 여러 개의 shot으로 나누게 됩니다. 여기서 scene detection은 ffmpeg에서 제공하는 방법을 사용합니다.
ffmpeg -i ${input_video} -filter_complex "select='gt(scene, ${threshold})',metadata=print:file=${output_file}" -vsync vfr img%03d.png위의 ${threshold}값은 0~1사이의 값이고 해당 값이 클수록 frame간의 변화가 커야 scene split이 일어납니다.

2.2 Encoding shots with various encoding parameters
각 shot에 대해서 여러 CRF와 Resolution 값에 대해 모두 encoding합니다. CRF값과 resolution의 값이 정확히 어떤 범위 및 값인지는 확인할 수는 없지만 해당 Netflix 논문을 참고했을 때 CRF는 16, 20, 24, 28, 32, 36, 40, 44, 48이고 resolution은 1080p, 720p, 540p, 432p, 360p, 270p, 216p를 사용하였습니다.
CRF는 9개, resolution은 7개입니다. 예를 들어 shot의 개수가 10개라면 총 encoding trial 횟수는 9*7*10=630번입니다. 그래서 해당 부분의 processing이 시간이 많이 듭니다.
2.3 Evaluating each encoded shots using VMAF
각각 shot에 대해 여러 CRF와 resolution값으로 encoding했다면 각 encoding된 shot이 원본과 비교했을 때 (1) 얼마나 distortion되었는 지, (2) 얼마나 압축되었는지 측정해야합니다. Distortion 측정 방법으로는 Netflix에서 제안한 VMAF를 사용하고 압축정도는bitrate로 계산합니다. 여기서 VMAF값은 0~100사이의 값을 가지고 값이 높을 수록 원본으로부터 distortion(왜곡)이 "안된것"입니다. 그래서 그대로 VMAF값을 사용하면 distortion의미와 반대이므로 아래와 같이 둘 중에 하나의 값으로 distortion 정도를 계산합니다.
- \( D_{Linear} (VMAF) = 100 - VMAF\)
- \( D_{Inverse} (VMAF) = \frac{1}{1+VMAF} \)

하나의 shot에 대해 여러 CRF, resolution으로 encoding하고 각각 encoded shot에 대해 bitrate, VMAF값을 구한 뒤에 R-D points를 graph로 visualization하면 다음과 같을 것입니다.

2.4 Extracting convex hull points for (R, D) points of each shot
위 그래프는 하나의 예시이지만 거의 대부분 shot에 대해서 convex hull모양의 R-D rate 그래프를 얻을 것입니다. 그럴 경우 Distortion T값을 기준으로 했을 때 a값을 가지는 180p가 b값을 가지는 144p보다 bitrate가 더 작은 것을 확인가능합니다. 즉, convex hull에 포함되는 point들이 특정 bitrate에서 가장 distortion이 낮은 것을 의미하고 또한 특정 distortion에서 가장 bitrate가 낮은 것을 의미합니다.
convex hull points들이 각 axis에서 가장 효율적인 encoded shot이므로 아래와 같이 convex hull points들만 뽑도록 합니다.
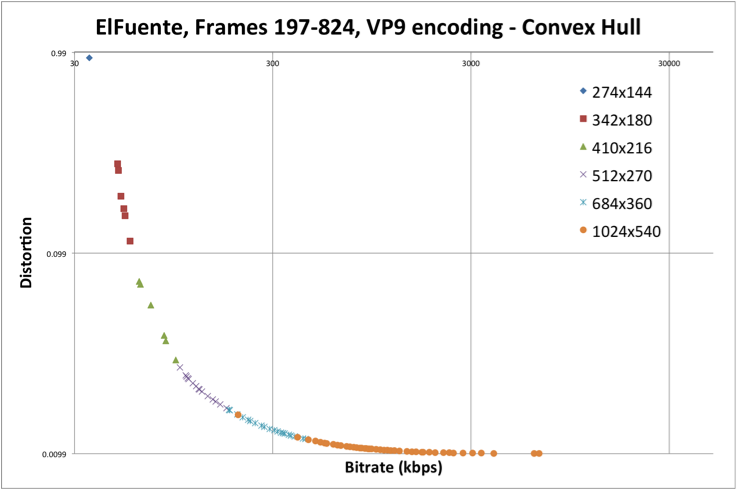
위 그래프처럼 convex hull points들만 뽑기 위해서 scipy.spatial.ConvexHull를 사용하시면 됩니다.
2.5 Constant slope principle for convex hull points of all shots
이제 아래와 같이 각 shot마다 convex hull points를 뽑인 상태입니다.

이 상태에서 각 shot마다 "최적의 encoded shot을 뽑아"서 concatenate하여 최종 per-shot encoding의 결과를 만들게 됩니다. 그렇다면 어떻게 최적의 encoded shot을 뽑을까요?
바로 constant slope principle을 이용하게 됩니다. Constant slope principle은 Integer Programming(IP) 문제랑 거의 같습니다. (저는 그냥 같다고 봅니다..ㅋㅋ) 그래서 풀어얘기하자면 constraint(e.g. 93 VMAF)를 만족하면서 objective function(e.g. bitrate 최소화)을 최대 or 최소화 시키는 알고리즘입니다. 즉, 각 shot마다 어떤 convex hull point을 골라야 (concatenate했을 때) 위의 constraint를 만족하면서 objective function을 최적화할 수 있는 지 알려주는 알고리즘이 constant slope priciple입니다.
(아시겠지만 convex hull points들이 continous한 값을 가지지 않고 discrete한 값을 가지므로 IP 문제입니다.)
Integer Programming 예시

per-shot enocoding으로 예를 들면 problem은 선택된 encoded shot들의 bitrate합이 Minimize되도록 할 것이고 subject to로는 선택된 encoded shot들의 평균 VMAF값이 93으로 설정하면 됩니다.
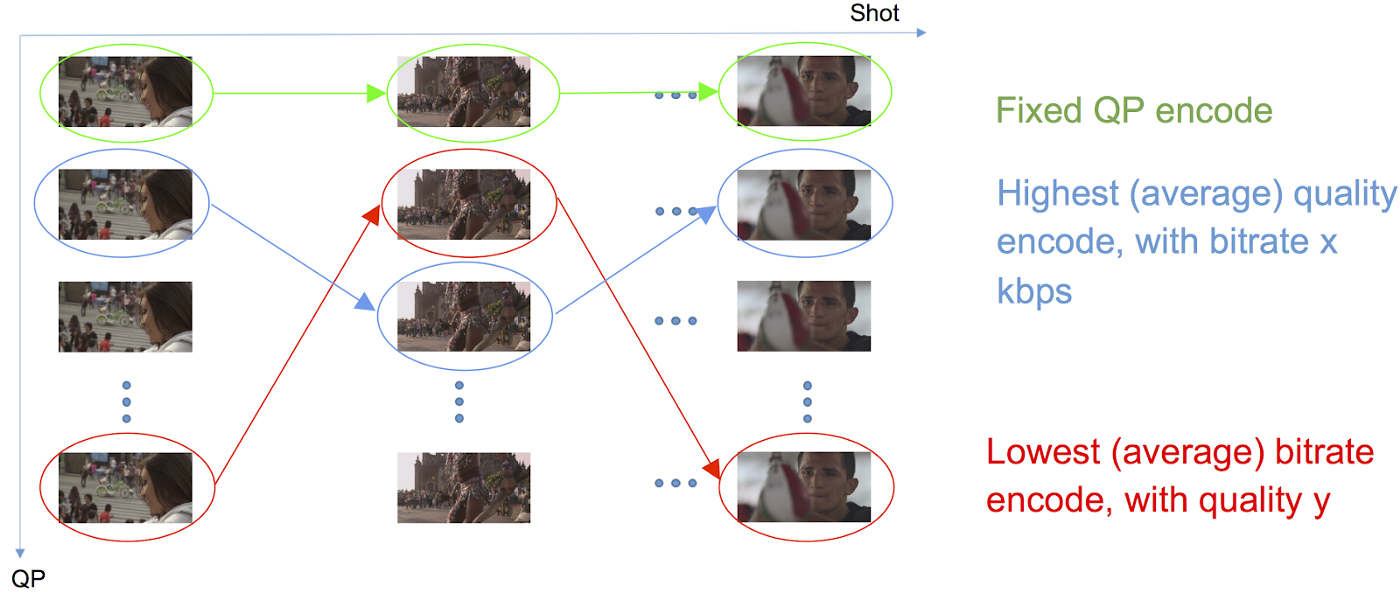
위 그림처럼 constraint를 bitrate로 주었을 때는 파란색 경로를 따라 평균 visual quality가 가장 높도록(distortion이 낮도록) 각 encoded shot들이 선택된 것을 볼 수 있지만 반대로 constraint를 visual quality로 주었을 때 빨간색 경로를 따라 평균 bitrate가 가장 낮도록 encoded shot들이 선택된 것을 볼 수 있다.
(constraint는 개발자가 주는 특정한 값입니다.)
2.6 concatenate selected convex hull points
마지막으로 위의 constant slope principle을 통해 선택된 (각 shot별로) encoded shot을 concatenate하면 최종 per-shot encoding의 결과물 video가 생성된다.
3. Results
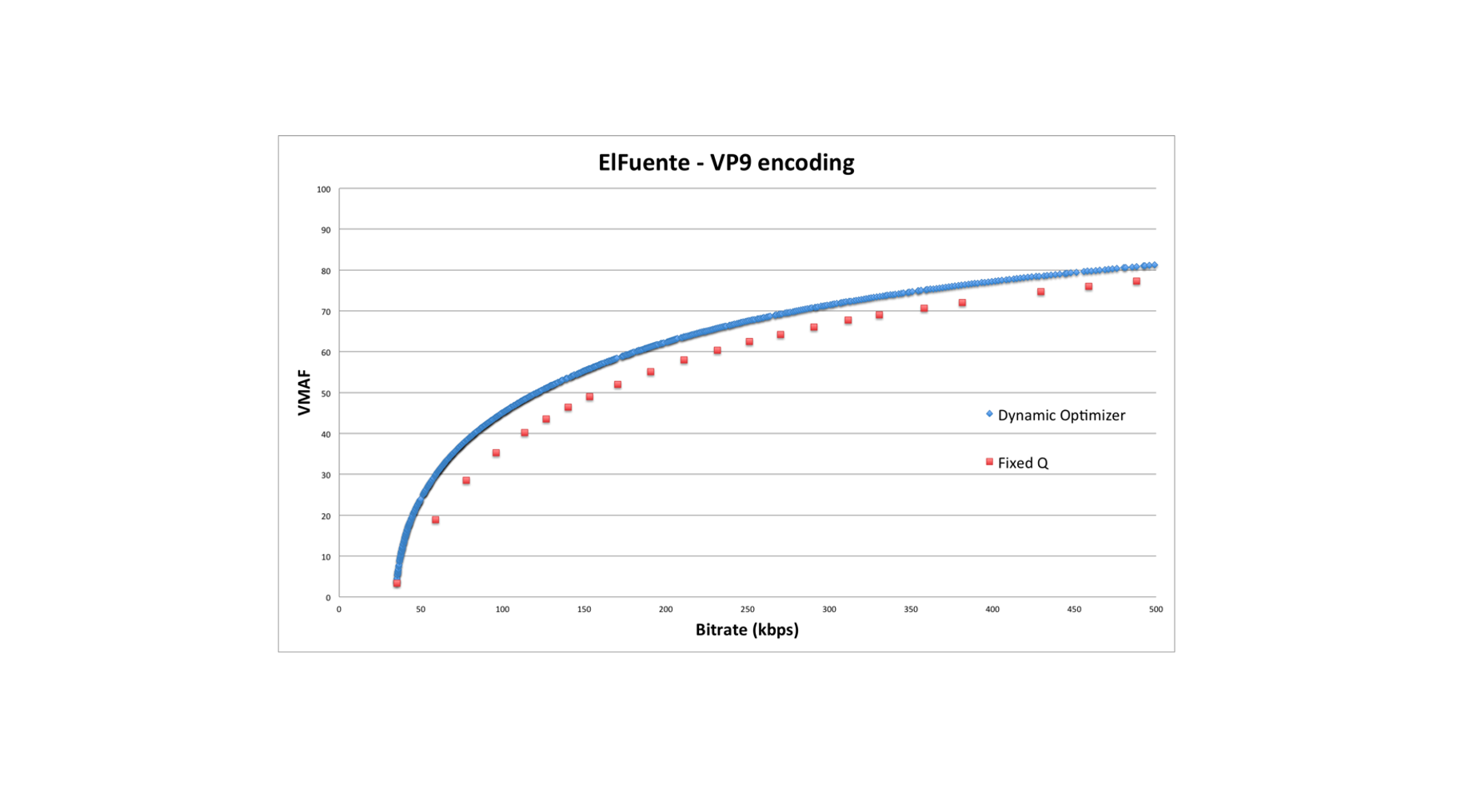
Conventional encoding(Fixed Q)과 비교했을 때 per-shot encoding(Dynamic Optimizer)의 성능은 아래와 같다고 합니다. 같은 distortion기준으로 per-shot encoding의 bitrate가 15~20%정도 적은 것을 확인가능합니다. 굳!

'Computer Science' 카테고리의 다른 글
| VMAF Optimization과 VMAF NEG 이해 (0) | 2024.02.01 |
|---|---|
| Per-title Encoding 설명 (0) | 2022.12.03 |
| VMAF score 란? (0) | 2022.07.09 |
| Python (2) Dict와 Set 차이 (0) | 2022.05.22 |
| Python (1) List와 Tuple 차이 (0) | 2022.05.20 |