1. Introduction
1.1 Motivation
The existing methods for object detection mainly have two problems.
(i) Most previous works have developed network structures for cross-scale feature fusion. However, they usually contribute to the fused output feature unequally.
(ii) While previous works mainly rely on bigger backbone networks or larger input image sizes for higher accuracy, scaling up feature network and box/class prediction network is also critical when taking into account both accuracy and efficiency.
1.2 Goal
For (i), they propose a weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multi-scale feature fusion. And, in order to solve (ii), they propose a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time.
Then, they call object detector that has these optimization methods as EfficientDet.
2. BiFPN
First, they formulate the multi-scale feature fusion problem that aims to aggregate features at different resolutions. And then, introduce ideas of BiFPN.
2.1 Problem Formulation
- \( \vec{P}^{ in } = ( P^{in}_{l_1}\) \(, P^{in}_{l_2} , \dots ) \): A list of multi-scale features
- \( P^{ in }_{ l_i }\): The feature at level \(l_i\)
- \( f \): Transformation
- (1) which is effective to aggregate different features
- (2) which outputs a list of new features \( \vec{P}^{ out } = f(\vec{P}^{ in }) \)
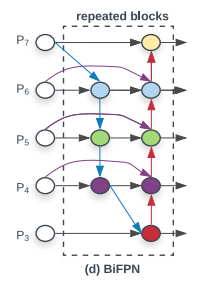
For an example of a multi-scale feature fusion, FPN [T. Y. Lin et al, 2017] has the conventional top-down pathway. The way of fusion describes in the below figure.

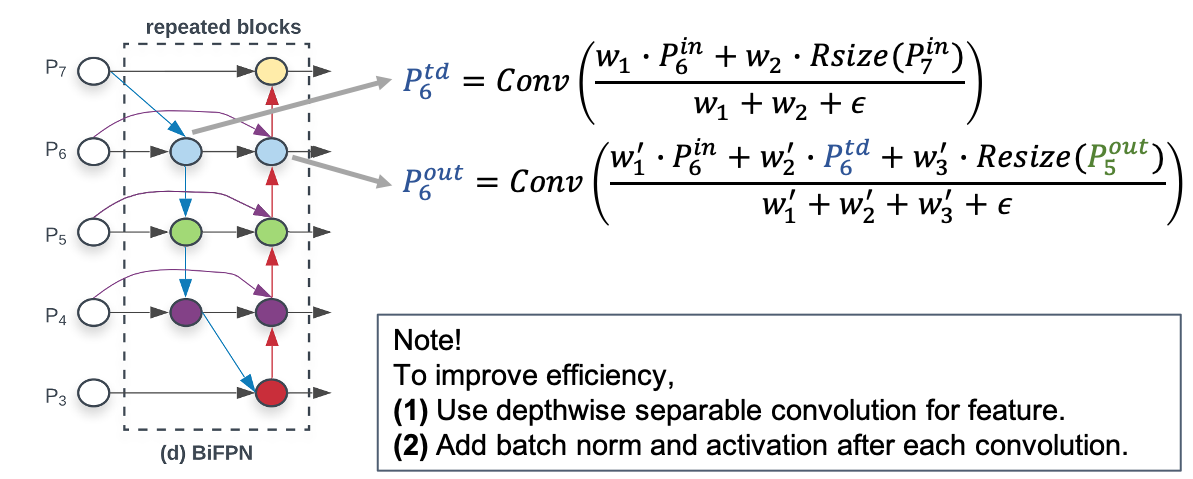
\(Resize\) is usually an upsampling or downsampling op for resolution matching, and \(Conv\) is a convolutional op for feature processing.
2.2 Cross-Scale Connections

The above figure represents multi-scale feature fusion method of previous approaches.
The problem of existing methods for feature fusion is:
- FPN: one-way information flow
- PANet: better accuracy, but the high cost of more parameters and computations
- NAS-FPN: requiring thousands of GPU hours
To improve model efficiency, this paper proposes several optimizations for cross-scale connections:
- Remove those nodes that only have one input edge.
- Why?
- One input edge with no feature fusion has less contribution to the feature network.
- This leads to a simplified bi-directional network.
- Why?
- Add an extra edge from the original input to the output node if they're at the same level.
- Why?
- This makes to fuse more features without adding much cost.
- Why?
- Treat each bidirectional path as one feature network and repeat the same layer multiple times.
- Why?
- ...
- Why?
2.3 Weighted Feature Fusion
When fusing features with different resolutions, a common way is to first resize them to the same resolution and then sum them up. At this point,
all previous methods treat all input features equally without distinction.
In this paper, in order to contribute to the output feature unequally from the input feature, the authors add an additional weight for each input and let the network learn the importance of each input feature.
Fast normalized fusion
\[
O = \sum_i \frac{w_i}{\epsilon + \sum_j w_j } \cdot I_i
\]
,where \( w_i \) is a learnable weight and \( w_i \geq 0 \) is ensured by appling a Relu after each \( w_i \), and \( \epsilon = 0.0001 \) is a small value to avoid numerical instability. And the value of each normalized weight falls between 0 and 1.
The final BiFPN integrates both the bidirectional cross scale connections and the fast normalized fusion. As a concrete example, they describe the two fused features at level 6 for BiFPN shown in Fig 2 (d):
3. EfficientDet
Based on BiFPN, they developed a detection model named EfficientDet.
3.1 EfficientDet Architecture
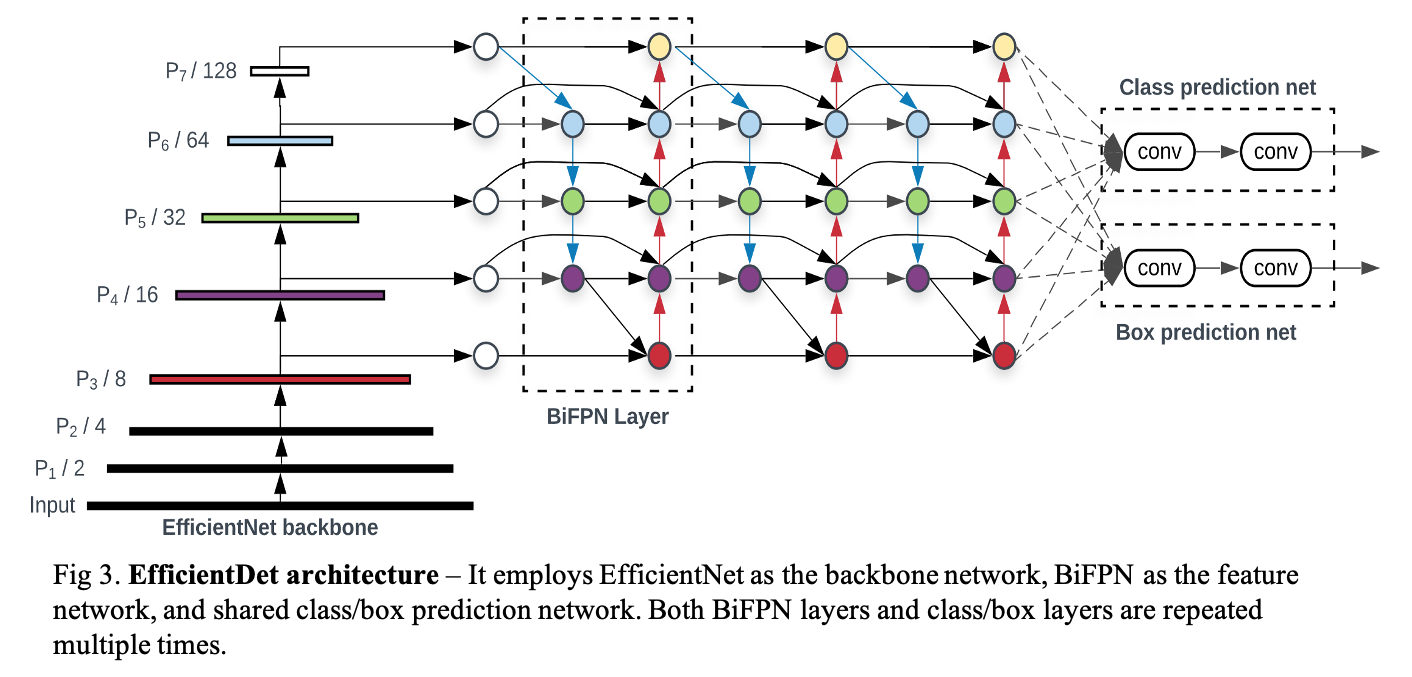
Fig 3. shows the overall architecture of EfficientDet, which is the one-stage detectors paradigm. They use ImageNet-pretrained EfficientNets as the backbone network.
BiFPN serves as the feature network and repeatedly applies top-down and bottom-up bidirectional feature fusion. These fused features are fed to a class and box network. The class and box network weights are shared across all levels of features.
3.2 Compound Scaling
Aiming at optimizing both accuracy and efficiency, they would like to develop a family of models that can meet a wide spectrum of resource constraints. A key challenge here is how to scale up a baseline EfficientDet model.
Therefore, they propose a new compound scaling method for object detection, which uses a simple compound coefficient \(\phi\) to jointly scale up all dimensions of backbone, BiFPN, class/box network, and resolution.
Backbone network
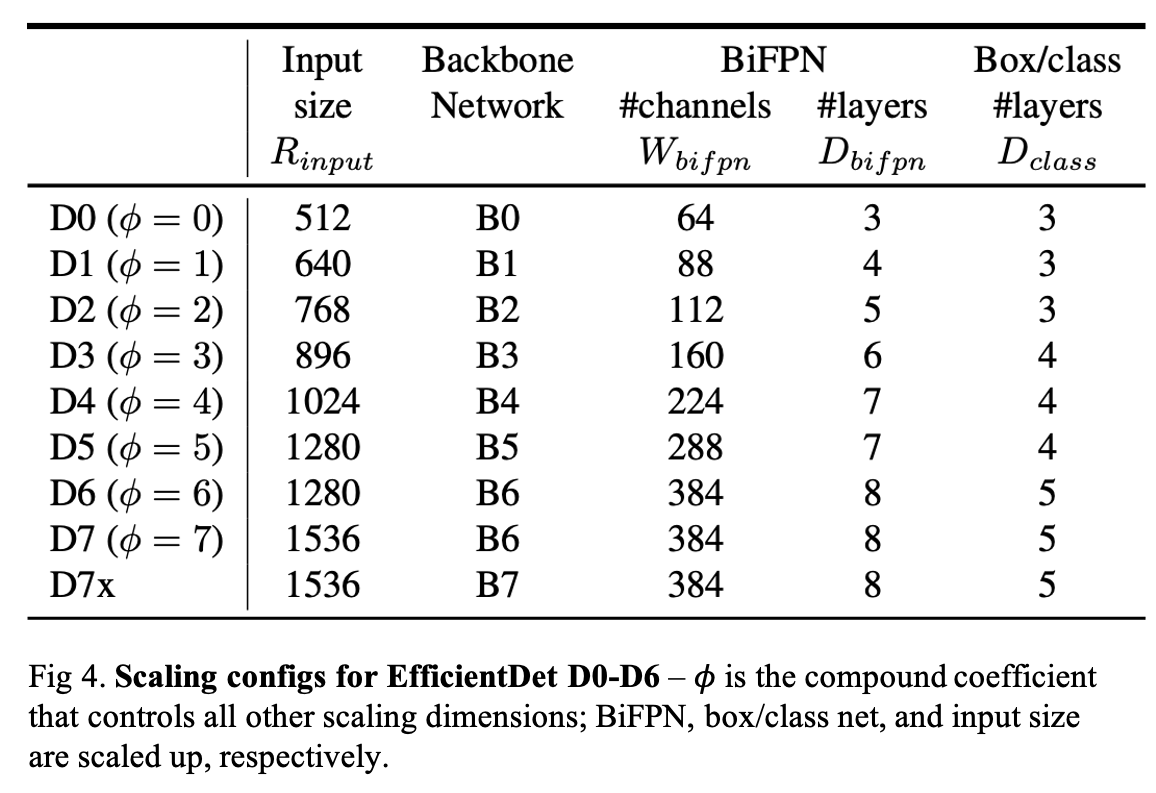
They reuse the same width/depth scaling coefficients of EfficientNet-B0 to B6.
BiFPN network
They linearly increase BiFPN depth \(D_{ bifpn }\) (#layer) since depth needs to be rounded to small integers. For BiFPN width \(W_{bifpn}\) (#channels), exponentially grow BiFPN width \(W_{bifpn}\) (#channels).
Especially, they perform a grid-search on a list of values {1.2, 1.25, 1.3, 1.35, 1.4, 1.45}, and pick the best value 1.35 as the BiFPN width scaling factor. Formally, BiFPN width and depth are scaled with the following equation:
\[
W_{bifpn} = 64 \cdot (1.35^{ \phi }), \quad D_{bifpn} = 3 + \phi \quad \cdots (1)
\]
Box/class prediction network
They fix their width to be always the same as BiPFN (i.e., \(W_{pred} = W_{ bifpn }\)), but linearly increase the depth (#layers) using equation:
\[
D_{ box } = D_{class } = 3 + \lfloor \phi / 3 \rfloor \quad \cdots (2)
\]
Input image resolution
Since feature levels 3-7 are used in BiFPN, the input resolution must be dividable by \(2^7=128\), so the linearly increase resolutions using the equation:
\[
R_{input} = 512 + \phi \cdot 128 \quad \cdots (3)
\]
Following Eq. (1), (2), (3) with different \(\phi\), they have developed EfficientDet-D0 (\(\phi\)=0 ) to D7 (\(\phi\)=7).
4. Experiment Setting
- Dataset: COCO 2017 detection datasets.
- Optimizer: SGD optimizer with momentum 0.9 and weight-decay 4e-5.
- Learning rate: linearly increased from 0 to 0.16 in the first training epoch then annealed down using cosine decay rule.
- Epoch size: 300 (D7/D7x is 600)
- Batch size: 128
- Batch norm: The synchronized batch norm is added after every convolution with batch norm decay 0.99 and epsilon 1e-3.
- Activation: SiLU (Swish-1) activation and exponential moving average with decay 0.9998.
- Loss: commonly-used focal loss with \(\alpha =0.25\) and \(\gamma =1.5\) and aspect ratio {1/2, 1, 2}.
- Data augmentation: horizontal flipping and scale jittering [0.1, 2.0], which randomly resizes images between 0.1x and 2.0x of the original size before cropping.
- Evaluation method: soft-NMS
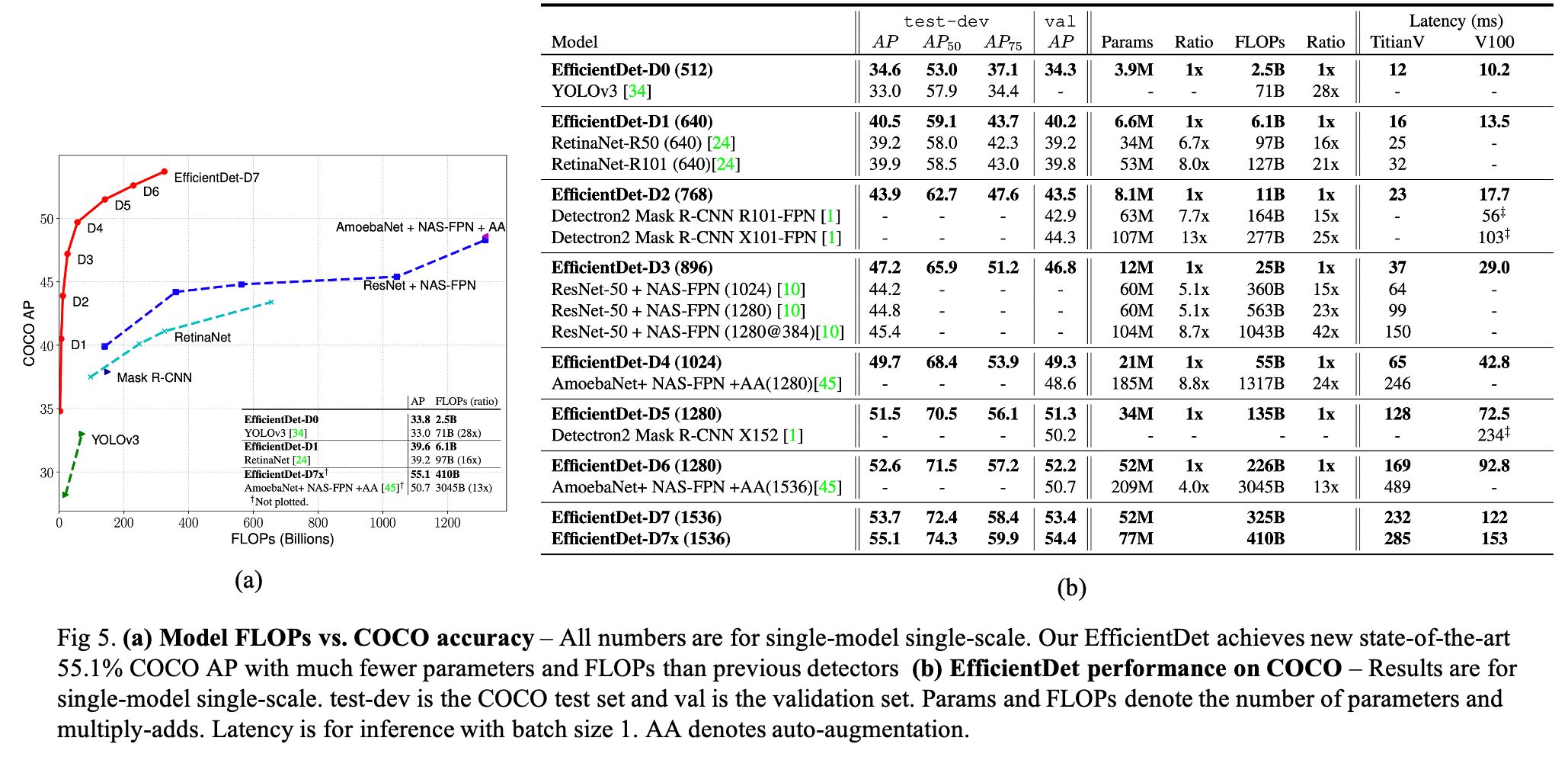
5. Experiment Result
Reference
Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and efficient object detection." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
'AI paper review' 카테고리의 다른 글
| Rate-Perception Optimized Preprocessing for Video Coding 논문 리뷰 (1) | 2023.12.31 |
|---|---|
| LoRA: Low-Rank Adaptation of Large Language Models 논문 리뷰 (0) | 2023.05.16 |
| Segment Anything 논문 리뷰 (0) | 2023.04.07 |
| GPT-1: Improving Language Understanding by Generative Pre-Training 논문 리뷰 (0) | 2023.02.13 |
| The Forward-Forward Algorithm: Some Preliminary Investigations 논문 리뷰 (0) | 2023.01.28 |