
오늘은 OpenAI의 GPT-1 논문을 리뷰하겠습니다.
1. Introduction
Natural Language Processing (NLP)를 포함한 대부분의 deep learning methods는 supervised learning을 통해 뛰어난 성능을 내는 모델을 만들었습니다. 뛰어난 성능을 내려면 기본적으로 많은 양의 labeled data을 필요로 합니다. 하지만 현실적으로 labeling은 사람이 하다 보니 정말~~ 많은 양의 labeled data는 구하기 힘들게 됩니다. 그에 비해 unlabeled data는 엄청 많습니다!
그래서, GPT-1은 수많은 unlabeled data로 unsupervised pre-training을 하고 labeled data로 supervised fine-tuning을 진행하는 semi-supervised방법을 사용하게 됩니다.
그럼 학습하는 데 unlabeled data 쓰는 게 어려움이 없냐?? 당연히 있습니다. Unlabeled data는 word-level information이상으로 활용하기가 어렵습니다.(성능 향상에 쓰이기 어렵다) 그 이유는 크게 2가지입니다.
- 특정 task(e.g. translation, question answering)에 transfer하기에 유용하다고 여겨지는 text representation을 학습하는 데 있어서 어떤 optimization objective이 효과적인지 알기 힘듦
- 학습된 text representation을 target task에 효과적으로 transfer하기 위한 일치된 의견(consensus)가 없음. 즉, 이러한 uncertainties가 language processing에서 semi-supervised learning방법을 발전시키기 어려움
이를 해결하기 위해 본 논문에서는 semi-supervised learning에서 다양한 task에 transfer하기에 적합한 universal representation을 학습하는게 목적입니다. 즉, 어떤 특정한 task를 수행하는 모델을 만들기 위해 해당 task와 관련된 domain의 unlabeled corpus를 필요로 하지 않습니다. GPT-1의 training은 two-stages procedure를 거칩니다.
- Two-stages Training Procedure
- Model의 initial parameters를 학습하기 위해 unlabeled data에 대해 language modeling objective를 사용
- 학습된 initial parameters을 target task에 적용시키기 위해 supervised learning 학습
GPT-1의 기본 model architecture는 Transformer를 사용합니다. Transformer는 long-term dependencies을 제어하기 위해 structured memory를 제공할 수 있고 이 구조는 다양한 task에 transfer하기 용이합니다. Transfer(fine-tuning) 할 때는 traversal-style approach를 기반으로 하는 task-specific input adaptations을 사용합니다. 이 approach는 structured text input을 하나의 contiguous sequence of tokens으로 만들 게 되고 이를 통해서 모델의 최소한의 변경만으로 효과적인 성능을 얻을 수 있습니다.
Traversal-style approach란?
아래 그림과 같이 다양한 task의 입력을 start token, delimiter(문장 구분), end tokens(Extract)으로 이루어지도록 하는 것. 이를 통해 모델의 최소한의 변경만으로 효과적인 fine-tuning가능함

2. Methods
Training procedure는 two-stages로 나뉩니다. (1) 수많은 unlabeled text data로 high-capacity language model을 학습하는 1번째 stage, (2) labeled data을 통해서 특정 task에 맞게 fine-tuning하는 2번째 stage를 거칩니다.
2.1 Unsupervised pre-training
Unlabeled된 token corpus \( U = \{ u_1, \ldots, u_n \} \)이 주어졌을 때 다음과 같이 likelihood를 최대화하기 위한 standard language modeling objective를 사용합니다.
\[
L_1(U) = \sum_i log P( u_i | u_{i-k}, \ldots, u_{i-1} ; \Theta) \quad \cdots Eq. (1)
\]
\( k \)는 context window size, \( P \)는 conditiional probability이며 이는 \( \Theta \) parameters로 구성된 network로 모델링되어있습니다. 해당 식을 풀이하자면 어떤 단어들을\(u_{i-k}, \ldots, u_{i-1} \)을 입력으로 주었을 때 그다음으로 나올 단어가 \( u_i \)일 확률이 높도록 \( \Theta \)을 학습하는 것입니다. 해당 network는 SGD optimizer로 학습했다고 합니다.
Language model로는 multi-layer Transformer Decoder를 사용하였습니다. Transformer Decoder는 기존의 Transformer의 encoder-decoder구조에서 encoder module을 제거하고(parameter반으로 줌) 원래의 input, output sentence를 a single sentence로 합쳐 해당 sentence를 모델의 입력으로 사용하는 구조입니다. 예를 들어, sequence-transduction data \( (m^1, \ldots , m^n) \mapsto (y^1, \ldots, y^{\gamma} ) \)을 \( (w^1, \ldots ,w^{n+\gamma+1}) = (m^1, \ldots , m^n, \delta, y^1, \ldots, y^\gamma) \) 로 치환하는 것을 의미합니다. ( \( \delta \)는 separator token)

해당 모델은 context tokens을 입력으로 multi-headed self-attention operation을 적용하였고 position-wise feed-forward layer를 통해 target token에 대한 output distribution을 산출하였습니다.
\[
\begin{array}{l} h_0 = U W_e + W_p , \cr h_l = transformer_block (h_{l-1} \forall i \in [1,n] , \cr P(u) = softmax(h_n W^T_e) \end{array} \quad \cdots Eq. (2)
\]
\( U = (u_{-k} , \ldots , u_{-1} ) \)은 tokens의 context vector, \(n\)은 layer 수, \(W_e \)는 token embedding matrix, \(W_p \) 은 position embedding matrix입니다.
2.2 Supervised Learning
Eq (1)을 통해 unsupervised learning을 완료했다면 supervised target task에 맞게 fine-tuning하게됩니다. 논문에서는 labeled dataset \( C \)을 가정합니다. (각 instance는 input tokens \(x_1, \ldots, x_m \)과 label \(y\)으로 이루어짐) Input tokens은 pre-trained model의 입력으로 들어가 마지막 transformer의 activation \( h^m_l \)을 출력해 내고 (target task을 위해) 추가된 linear output layer( with parameter \(W_y \) )을 거쳐 최종 output \( y \)를 predict하게 됩니다.
\[
P(y | x^1 , \ldots , x^m ) = softmax(h^m_l W_y)\quad \cdots Eq. (3)
\]
Eq. (3)을 통해 나온 output \( P(y | x^1 , \ldots , x^m ) \)은 아래와 같은 objective function을 maximize하도록 학습됩니다.
\[
L_2 (C) = \sum_{(x,y)} log P (y| x^1 , \ldots , x^ m) \quad \cdots Eq. (4)
\]
추가적으로 (1) supervised model의 generalization ability를 향상시키고 (2) convergence를 가속화시키기 위해 fine-tuning시에 auxiliary objective function을 사용하였습니다. 아래와 같이 기존의 unsupervised learning에 사용했던 loss term \( L_1(C) \)도 추가하여서 supervised, unsupervised learning의 task모두 잘할 수 있도록 합니다. ( \( \lambda \)는 weight parameter입니다.)
\[
L_3 (C) = L_2(C) + \lambda L_1(C) \quad \cdots Eq. (5)
\]
2.3 Task-specific input transformations
Text classfication같은 task경우 위의 방법 그대로 fine-tuning가능하지만 question answering, textual entailment와 같은 다른 task에는 고유한 structured input을 필요로 합니다. 그렇다고 각 task의 input 형태에 따라 모델을 크게 변경해야 한다면 이는 customization하는 cost가 많이 듭니다. 이를 해결하기 위해 traversal-style approach를 사용합니다. 해당 방법은 structured input을 unsupervised learning을 통해 pre-trained model에 process할 수 있도록 ordered sequence로 바꾸게 됩니다.
아래와 같이 모든 task에 대해 input transformations은 랜덤하게 initialized start, end tokens ( \( \langle s \rangle ,\langle e \rangle \) ) 을 포함합니다.
2.3.1 Textual Entailment
위 그림과 같이 premise \( p \)와 hypothesis \( h \) token sequence들을 concatenate 합니다. 두 tokens을 구분하기 위해 delimiter(구분자) token \( $ \)을 사용합니다.
2.3.2 Similarity
해당 task에서는 두 문장 사이에 가능한 ordering모두 고려하여 input transformations하여 두 개의 input을 만들고 각각 독립적으로 transformer의 output representations \( h^m_l \)을 뽑아내고 element-wise하게 add operation하고 linear output layer을 거쳐 최종 output을 얻습니다.
2.3.3 Question Answering
Document \(z\), question \(q\)와 가능한 answer set \( { a_k} \)가 주어질 때 document context와 question을 한 묶음하고 각 가능한 answer을 delimiter token을 이용해 concatenate합니다. 즉, \( [z; q; $; a_k] \)형태의 여러 개의 input을 만듭니다. 각 input sentence는 독립적으로 model을 거친 다음 sofmax layer을 통해 normalize시켜 possible answer들에 대해 output distribution을 얻습니다.
3. Experiment
3.1 Setup
Unsupervised learning에 BooksCorpus dataset을 사용하였습니다. 7000개의 미출판된 책의 내용을 담고 있으며 장르도 어드벤쳐, 판타지, 로맨스로 다양합니다. 대체가능한 dataset으로는 1B Word Benchmark이며 sentence-level로 shuffled되어 long-range structure를 없앴습니다. Unsupervised learning을 통해 해당 corpus에서 18.4이라는 낮은 token level perplexity(복잡성)을 도출하였다고 합니다. (저 perplexity 어떻게 scoring하는 지 아시는 분 있으신가요..?)
It contains over 7,000 unique unpublished books from a variety of genres including Adventure,
Fantasy, and Romance. Crucially, it contains long stretches of contiguous text, which allows the
generative model to learn to condition on long-range information. An alternative dataset, the 1B
Word Benchmark, which is used by a similar approach, ELMo [44], is approximately the same size
3.1.1 Model specifications
모델은 original transformer의 decoder부분만 사용하였습니다. masked self-attention heads(768 dim and 12 attentions heads)가 포함된 12 layer로 이루어져 있습니다. Position-wise feed-forward networks을 위해 3,072 dimension의 inner state를 사용하였습니다.
- Model: original transformer의 decoder부분
- Masked self-attention heads(768 dim and 12 attentions heads)가 포함된 12 layers
- Position-wise feed-forward networks을 위해 3,072 dimension의 inner state를 사용
- Layer-Norm 사용됨
- N(0, 0.02)로 weight initialization
- Activation function으로 Gasuusian Error Linear Unit (GELU)사용
- Optimizer: Adam
- Learning rate: 2.5e-4
- Scheduler: cosine annealing
- Epochs: 100
- Batch size: 64
- Token length: 512
- bytepair encoding (BPE) vocabulary 사용
- 40,000 merges와 residual, embedding, attention dropouts 포함
- 0.1 regularization
- modified L2 regularization 사용
- 모든 non biasd와 gain weights에 대해 w=0.01
- ftfy library을 사용하여 BooksCorpus의 raw text를 정리
- spaCy tokenizer 사용
3.2.2 Fine-tuning details
- 명시되지 않았으면 unsupervised pre-training에 썼던 hyperparameter를 그대로 사용
- 0.1 rate의 dropout을 classifier에 추가
- Learning rate: 6.25e-5
- Batch size: 32
- Epochs: 3 (3이면 충분하다고 합니다.)
- Scheduler: linear learning rate decay
- 0.2%의 warm-up training
- \( \lambda \): 0.5
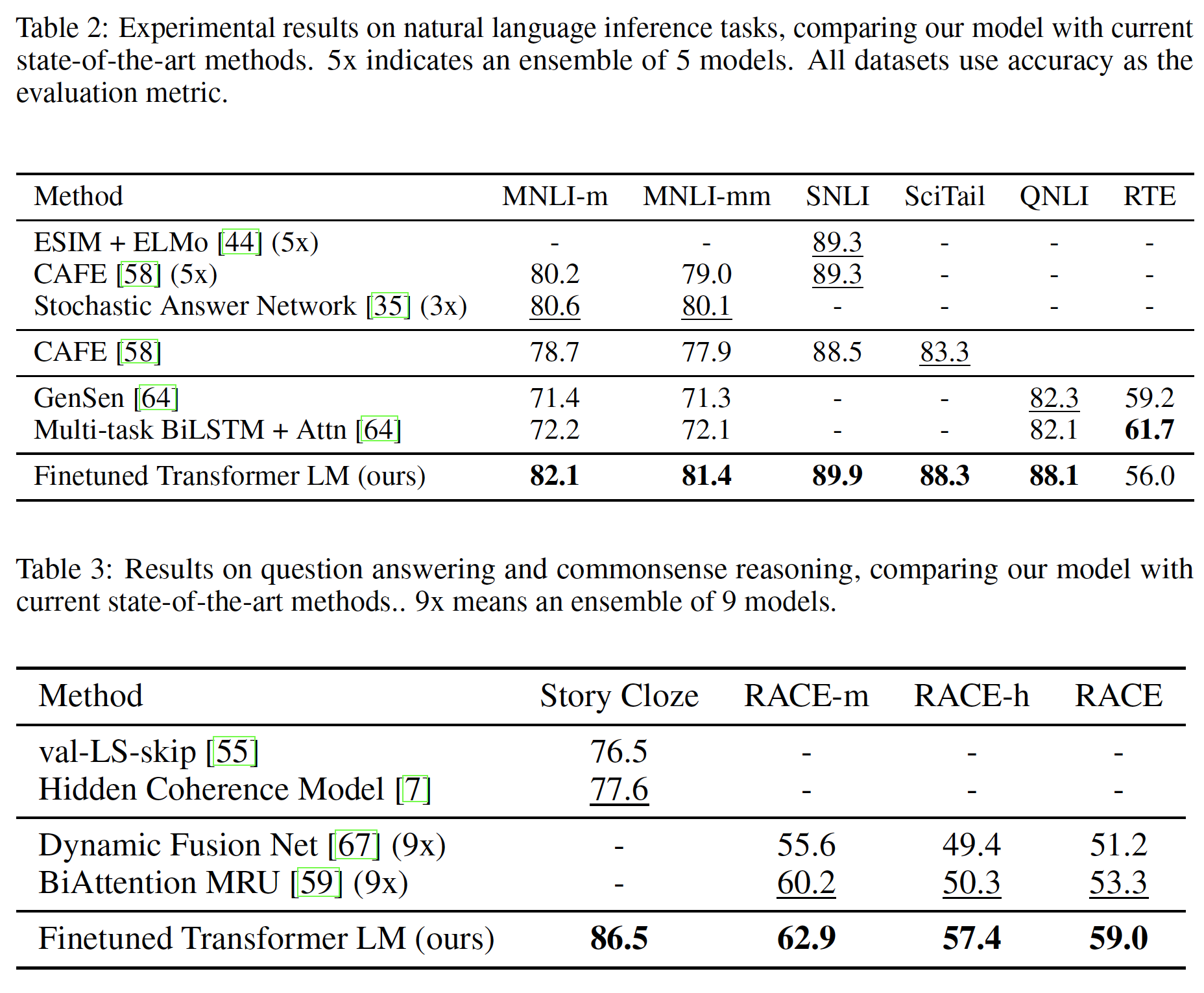
3.2 성능
성능은 기존보다 당연히 좋을 거라 제 관심사가 아니므로 결과표만 보여드립니다.
'AI paper review' 카테고리의 다른 글
| Rate-Perception Optimized Preprocessing for Video Coding 논문 리뷰 (1) | 2023.12.31 |
|---|---|
| LoRA: Low-Rank Adaptation of Large Language Models 논문 리뷰 (0) | 2023.05.16 |
| Segment Anything 논문 리뷰 (0) | 2023.04.07 |
| The Forward-Forward Algorithm: Some Preliminary Investigations 논문 리뷰 (0) | 2023.01.28 |
| EfficientDet Scalable and Efficient Object Detection (0) | 2022.03.11 |