1. Introduction
Filter Decomposition (FD): Decomposing a weight tensor into multiple tensors to be multiplied in a consecutive manner and then getting a compressed model.
1.1 Motivation
Well-known low-rank approximation (i.e. FD) methods, such as Tucker or CP decomposition, result in degraded model accuracy because decomposed layers hinder training convergence.
1.2 Goal
To tackle this problem, they propose a new training technique, called DeepTwist, that finds a flat minimum in the view of low-rank approximation without a decomposed structure during training.
That is, they retain the original model structure without considering low-rank approximation. Moreover, because the method preserves the original model structure during training, 2-dimensional low-rank approximation demanding lowering (such as im2col) is available.
2. Training Algorithm for Low-Rank Approximation
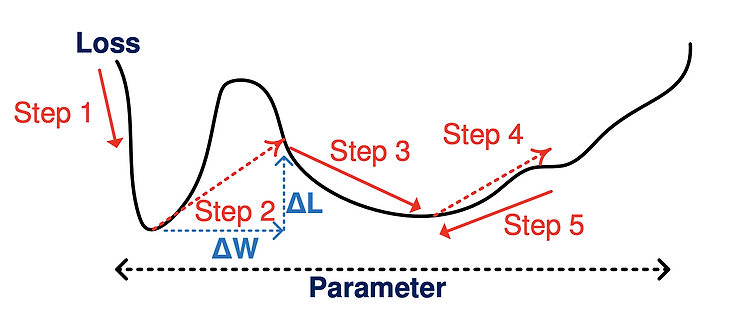
Note that FD methods incur the accuracy drop from the original network because of an approximation error given a rank. If so, in terms of loss surface, which position of parameters is appropriate before applying FD in the below figure?

As you already expect, the right position of parameters is less sensitive to accuracy drop (loss variance). That is, the underlying principle of the proposed training algorithm is to find a particular local minimum of flat loss surface, robust to parameter errors induced by low-rank approximation.
The proposed scheme preserves the original model structure and searches for a local minimum well suited for low-rank approximation. The training procedure for low-rank approximation, called DeepTwist, is illustrated in Fig. 1.
- Step by Step
- Training
- At each weight distortion step, parameters are decomposed into multiple tensors following low-rank approximation (e.g. CP, tucker).
- Those decomposed tensors are multiplied to reconstruct the original tensor form.
- If a particular local minimum is not flat enough, training procedure escapes such a local minimum through a weight distortion step (step 2).
- Otherwise, the optimization process is continued in the search space around a local minimum (steps 4 and 5).
- Training
2.1 Determining the best distortion step
Determining the best distortion step
using a local quadratic approximation (taylor series).
- Parameter set:
- Set of parameters at a local minimum:
- Hessian of
- Learning rate:
Then,
Thus, after
Correspondingly, large
3. Tucker Decomposition Optimized by DeepTwist
First of all, Tucker decomposition is described as below:
- Original 4D kernel tensor:
- Kernel dimension:
- Input feature map size:
- Output feature map size:
- Kernel dimension:
- Approximated 4D kernel tensor:
- Reduce kernel tensor:
- The rank for input feature map dimension:
- The rank for output feature map dimension:
- 2D filter matrices to map
Each component is obtained to minimize the Frobenius norm of
DeepTwist training algorithm is conducted for Tucker decomposition as follows:
- Perform normal training for
- Calculate
- Replace
- Go to Step 1 with updated
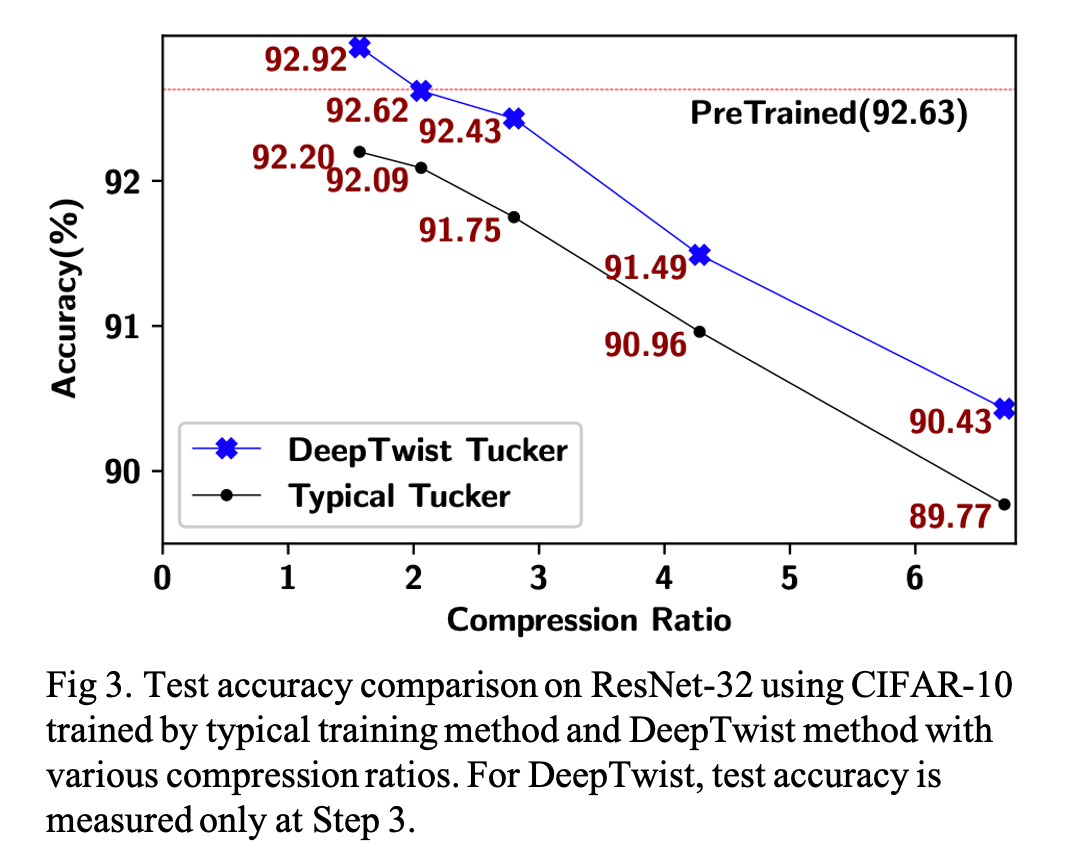
Using the pre-trained ResNet-32 model with CIFAR-10 dataset, compare two training methods for Tucker decomposition: 1) typical training with a decomposed model and 2) DeepTwist training (
4. 2-Dimensional SVD Enabled by DeepTwist
4.1 Issues of 2D SVD on Convolution Layers
Convolution can be performed by matrix multiplication if an input matrix is transformed into a Toeplitz matrix with redundancy and a weight kernel is reshaped into a T × (S × d × d) matrix (i.e., a lowered matrix). Then, commodity computing systems (such as CPUs and GPUs) can use libraries such as Basic Linear Algebra Subroutines (BLAS) without dedicated hardware resources for convolution.
For BLAS-based CNN inference, reshaping a 4D tensor
4.2 Tiling-Based SVD for Skewed Weight Matrices
A reshaped kernel matrix
to be
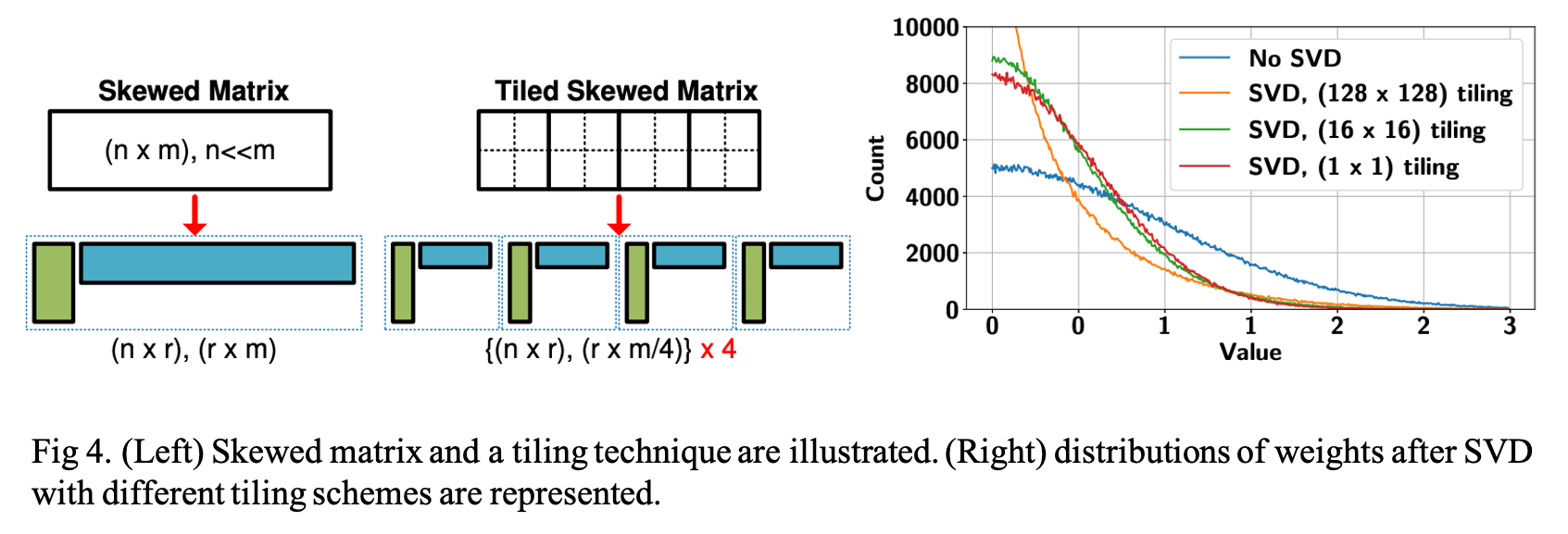
They tested a (1024 × 1024) random weight matrix in which elements follow a Gaussian distribution. A weight matrix is divided by (1×1), (16×16), or (128×128)tiles (then, each tile is a submatrix of (1024×1024), (64×64), or (8×8) size). Each tile is compressed by SVD to achieve the same overall compression ratio of 4× for all of the three cases. As described in Fig. 4. (on the right side), increasing the number of tiles tends to increase the count of near-zero and large weights.
They applied the tiling technique and SVD to the 9 largest convolution layers of ResNet-32 using the CIFAR-10 dataset. Weights of selected layers are reshaped into 64 × (64 × 3 × 3) matrices with the tiling configurations described in Table 1. DeepTwist performs training with the same learning schedule and SD(=200) used in Section 3.

Reference
Lee, Dongsoo, et al. "Learning low-rank approximation for cnns." arXiv preprint arXiv:1905.10145 (2019).
'AI paper review > Model Compression' 카테고리의 다른 글
| Learning Features with Parameter-free Layers 논문 리뷰 (0) | 2022.04.28 |
|---|---|
| Few Sample Knowledge Distillation for Efficient Network Compression (0) | 2022.03.11 |
| Knowledge Distillation via Softmax Regression Representation Learning (0) | 2022.03.10 |
| EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning (0) | 2022.03.10 |
| Data-Free Knowledge Amalgamation via Group-Stack Dual-GAN (0) | 2022.03.09 |
- 1. Introduction
- 1.1 Motivation
- 1.2 Goal
- 2. Training Algorithm for Low-Rank Approximation
- 2.1 Determining the best distortion step SD
- 3. Tucker Decomposition Optimized by DeepTwist
- 4. 2-Dimensional SVD Enabled by DeepTwist
- 4.1 Issues of 2D SVD on Convolution Layers
- 4.2 Tiling-Based SVD for Skewed Weight Matrices
- Reference