
1. Introduction
Knowledge Distillation: Dealing with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance.

1.1 Motivation
The authors of this paper try to make the outputs of student network be similar to the outputs of the teacher network. Then, they have advocated for a method that optimizes not only the output of softmax layer of the student network but also the output feature of its penultimate layer. Because optimizing the output feature of the penultimate layer is related to representation learning, they propose two approaches.
1.2 Goal
The first thing is a direct feature matching approach that focuses on optimizing the student penultimate layer. Because the first approach detached from the classification task, they propose the second approach that is to decouple representation learning and classification and utilize the teacher's pre-trained classifier to train the student's penultimate layer feature.
2. Definition
- Class logits
- Class logits
3. Method
In this work, the authors aim to minimize the discrepancy between the representations \(h^T\( and \(h^S\(. To do this, they propose to use two losses.
The first one is an
where
They found
Let us denote by
At this point, the following two observations is: (1) If
Now write Hinton KD loss in a similar way:
When comparing Eq. (3) and Eq. (4), because
Overall, in this method, they train the student network using three losses:
where
The algorithm of this method is described on below.
4. Experiment Results
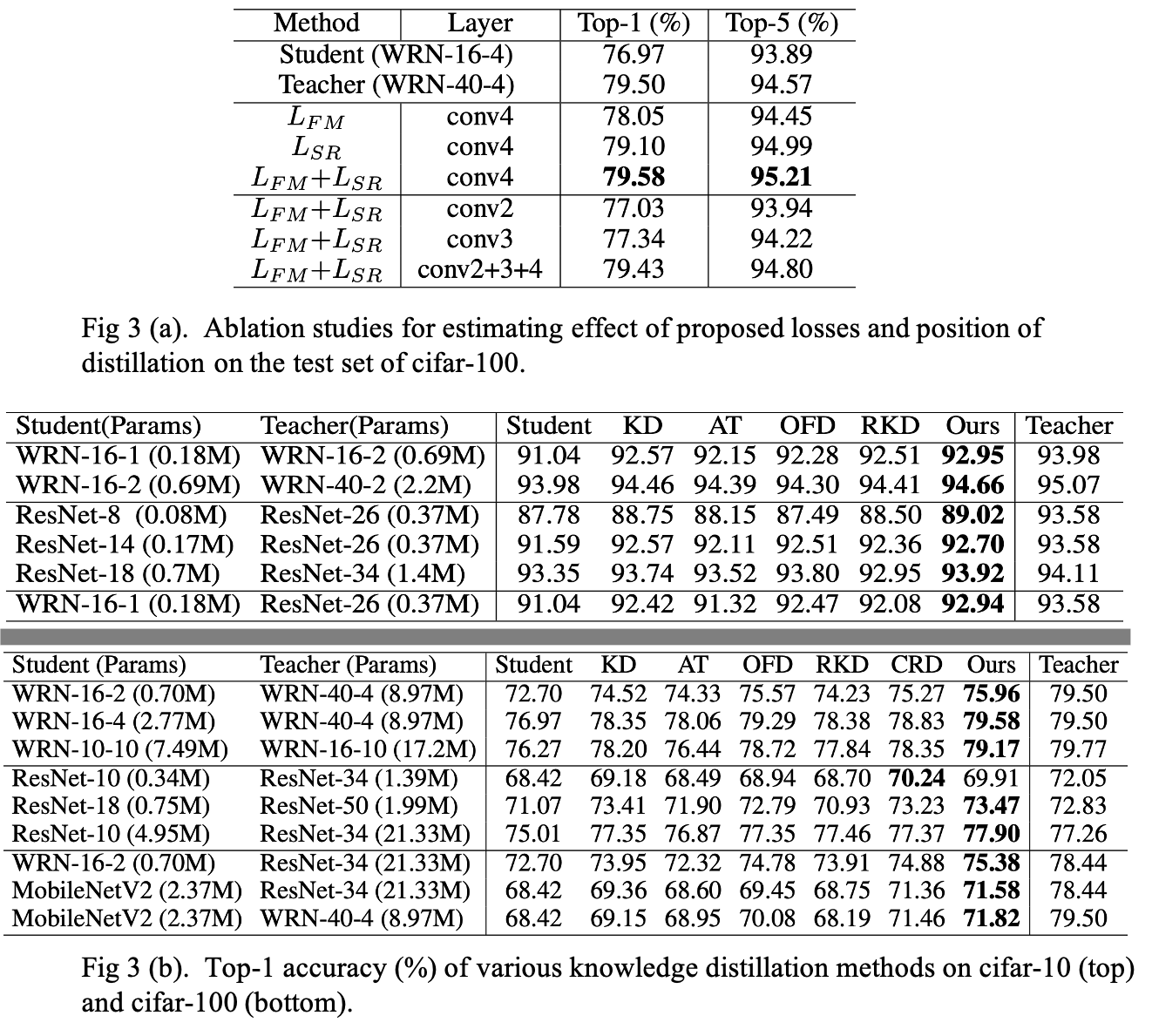
Reference
Yang, Jing, et al. "Knowledge distillation via softmax regression representation learning." International Conference on Learning Representations. 2020.
Github Code: Knowledge Distillation via Softmax Regression Representation Learning
'AI paper review > Model Compression' 카테고리의 다른 글
| Learning Low-Rank Approximation for CNNs (0) | 2022.03.12 |
|---|---|
| Few Sample Knowledge Distillation for Efficient Network Compression (0) | 2022.03.11 |
| EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning (0) | 2022.03.10 |
| Data-Free Knowledge Amalgamation via Group-Stack Dual-GAN (0) | 2022.03.09 |
| Dreaming to Distill Data-free Knowledge Transfer via DeepInversion (0) | 2022.03.09 |