
1. Data-free Knowledge distillation
Knowledge distillation: Dealing with the problem of training a smaller model (Student) from a high capacity source model (Teacher) so as to retain most of its performance.
As the word itself, We perform knowledge distillation when there is no original dataset on which the Teacher network has been trained. It is because, in real-world, most datasets are proprietary and not shared publicly due to privacy or confidentiality concerns.
In order to perform data-free knowledge distillation, it is necessary to reconstruct a dataset for training Student network. Thus, in Data-Free Learning of Student Networks, we propose a novel framework, named as Data-Free Learning (DAFL), for training efficient deep neural networks by exploiting generative adversarial networks (GANs).
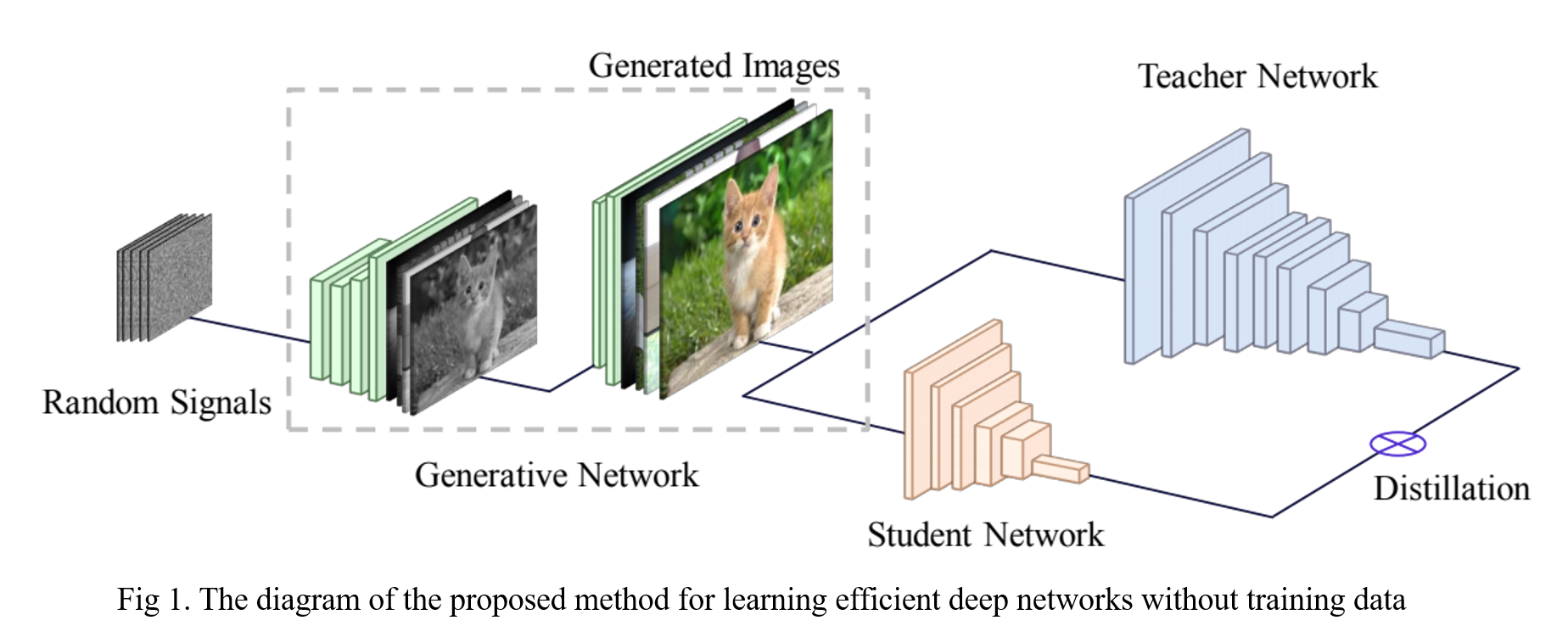
2. Method
2.1 Teacher-Student Interactions
Knowledge Distillation (KD) is a widely used approach to transfer the output information from a heavy network to a smaller network for achieving higher performance. To describe this formally, let \(\mathcal{N}_T\) and \(\mathcal{N}_S\) denote the original pre-trained CNN (teacher network) and the desired portable network (student network). The student network can be optimized using the following loss function based on KD:
\[
L_{KD}=\frac{1}{n} \sum_i \mathcal{H}_{cross}(y^i_S, y^i_T). \quad \cdots Eq.(1)
\]
where \(\mathcal{H}_{cross }\) is the cross-entropy loss, \(y^i_T= \mathcal{N}_T(x^i)\) and \(y^i_S=\mathcal{N}_S(x^i)\) are the outputs of the teacher network \(\mathcal{N}_T\) and student network \(\mathcal{N}_S\), respectively.
2.2 GAN for Generating Training Samples
In order to learn portable network without original data, we exploit GAN to generate training samples utilizing the available information of the given network.
GANs consist of a generator \(G\) and a discriminator \(D\). \(G\) is expected to generate desired data while \(D\) is trained to the differences between real images and those produced by the generator as follows:
\[
L_{GAN}= \mathbb{E}_y [ log D(y) ] + \mathbb{E}_z [log (1-D(G(z)))] \quad \cdots Eq. (2)
\]
where \(x\) is the desired data and \(z\) is an input noise vector of \(G\). However, in the absence of training data, it is thus impossible to train the discriminator as vanilla GANs. And then, this affects that we cannot also train the generator.
To tackle this problem, we propose to regard the given teacher network as a fixed discriminator. Therefore, \(G\) can be optimized directly without training \(D\) together, i.e the parameters of original network \(D\) are fixed during training \(G\).
However, given the teacher deep neural network as the discriminator, the output is to classify images to different concept sets, instead of indicating the reality of images. The loss function
in vanilla GANs is therefore inapplicable for approximating the original training set. Thus, we introduce several new loss functions that satisfy the following properties.
(i) The outputs are encouraged to be one-hot vectors
- A set of random vector: \(\{ z^1, \cdots ,z^n \}\)
- Images generated from random vectors: \(\{ x^1, \cdots , x^n\}\), where \(x^i=G(z^i)\)
- Outputs from the teacher network: \(\{ y^1_T, \cdots, y^n_T \} ;\) with \(y^i_T=\mathcal{N}_T (x^i)\)
- The predicted labels: \(\{ t^1, \cdots, t^n \}\) caculated by \(t^i=argmax_j ,(y^i_T)_j\)
If images generated by \(G\) follow the same distribution as that of the training data of the teacher, they should also have similar outputs as the training data. We thus introduce the one-hot loss by taking \(\{ t^1, \cdots, t^n \}\) as pseudo ground-truth labels.
\[
L_{oh}=\frac{1}{n}\sum_i \mathcal{H}_{ cross } (y^i_T,t^i) \quad \cdots Eq.(3)
\]
By introducing the one-hot loss, we expect that a generated image can be classified into one particular category concerned by the teacher network with a higher probability.
(ii) Intermediate features extracted by convolution layers are important representations of input images
We denote features of \(x^i\) extracted by the teacher network as \(f^i_T\), which corresponds to the output before the fully-connected layer. Since filters in the teacher DNNs have been trained to extract intrinsic patterns in training data, feature maps tend to receive higher activation value if input images are real rather than some random vectors.
Hence, we define an activation loss function as:
\[
L_a=-\frac{1}{n} \sum_i \Vert f^i_T\Vert_1, \quad \cdots Eq. (4)
\]
where \(\Vert \cdot \Vert_1\) is the \(l_1\) norm.
(iii) The number of training examples in each category is usually balanced
We employ the information entropy loss to measure the class balance of generated images. Specifically, given a probability vector \(p= (p_1, \cdots, p_k)\), the information entropy, which measures the degree of confusion, of \(p\) is caculated as \( \mathcal{H}_{info} (p)= -\frac{1}{k} \sum_i p_i log (p_i) \). The value of \(\mathcal{H}_{info}(p)\) indicates the amount of information that \(p\) owns, which will take the maximum when all variables to equal to \(\frac{1}{k}\). When we apply the information entropy to output vectors \(\{ y^1_T, \cdots, y^n_T \} \;\), The information entropy loss of generated images is defined as
\[
L_{ie}=-\mathcal{H}_{ info } (\frac{1}{n} \sum_i y^i_T). \quad \cdots Eq. (5)
\]
When the loss takes the minimum, every element in vector \(\{ y^1_T, \cdots, y^n_T \} \;\) would equal to \(\frac{1}{k}\), which implies \(G\) could generate images of each category with roughly the same probability.
By combining the aforementioned three loss functions, we obtain the final objective funcion
\[
L_{Total}=L_\{oh\}+\alpha L_\{a\}+\beta L_\{ie\}, \quad \cdots Eq. (6)
\]
where \(\alpha\) and \(\beta\) are hyper paramerters for balancing three different terms. The algorithm of DAFL is described in Algorithm 1.

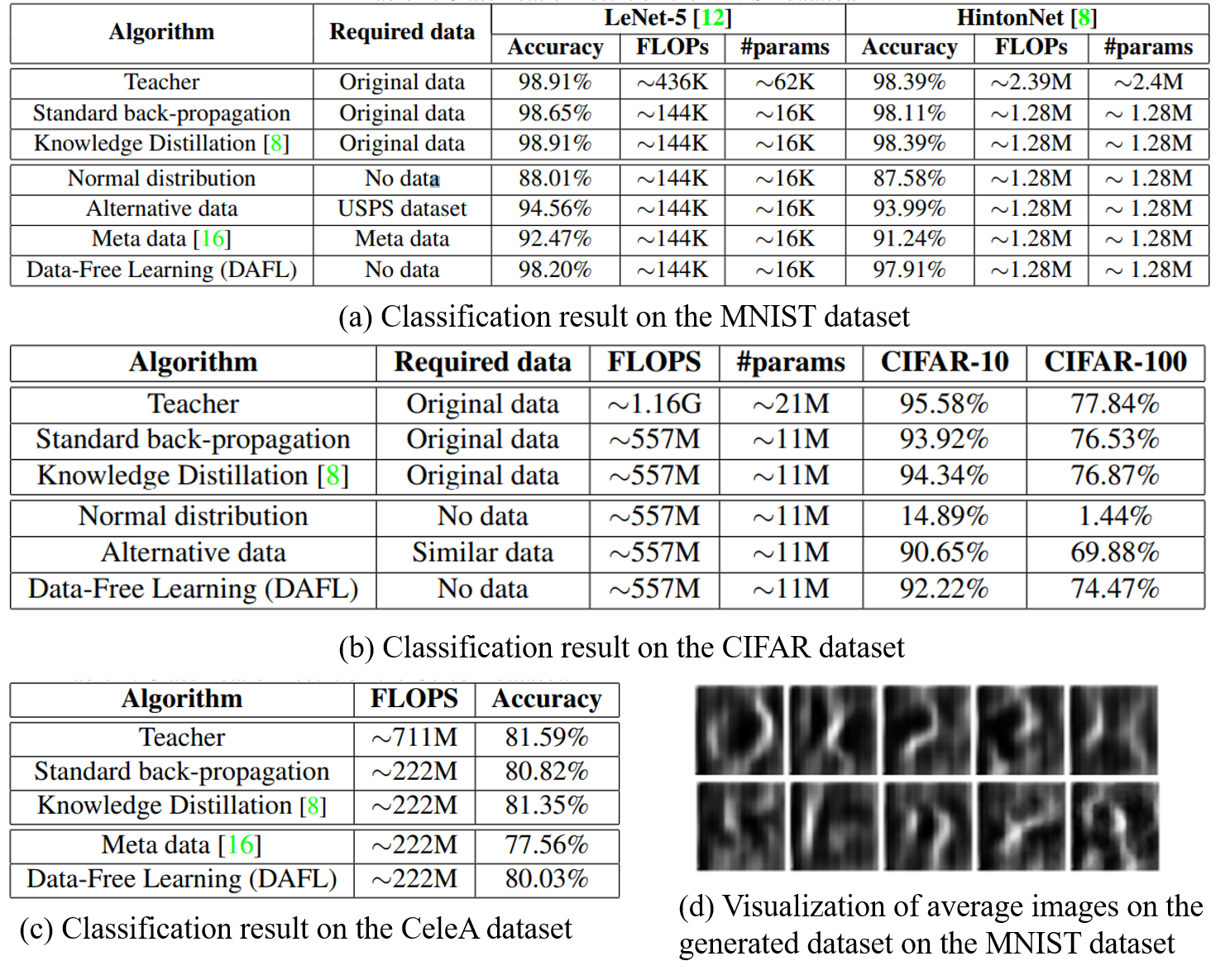
3. Experiment Setting & Result
Reference
Chen, Hanting, et al. "Data-free learning of student networks." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
'AI paper review > Model Compression' 카테고리의 다른 글
| EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning (0) | 2022.03.10 |
|---|---|
| Data-Free Knowledge Amalgamation via Group-Stack Dual-GAN (0) | 2022.03.09 |
| Dreaming to Distill Data-free Knowledge Transfer via DeepInversion (0) | 2022.03.09 |
| Zero-Shot Knowledge Transfer via Adversarial Belief Matching (0) | 2022.03.08 |
| Zero-Shot Knowledge Distillation in Deep Networks (0) | 2022.03.08 |